
前言
Yolov8在训练完成之后,默认会在runs/detect/目录下创建训练结果目录默认名称以train为前缀,把训练的过程一些参数与结果示意图保存到此目录,这里面包含是目标检测性能指标,如下图:
评估目标检测性能指标通常涉及以下步骤:
准确率(Accuracy):
表示正确预测的目标数量与总预测数量的比率。
精确率(Precision):
表示模型正确预测为正样本的样本数量占所有预测为正样本的样本数量的比例。
召回率(Recall):
表示模型正确预测为正样本的样本数量占所有实际正样本的样本数量的比例。
F1分数(F1 Score):
综合考虑精确率和召回率,是精确率和召回率的调和平均数。
IoU(Intersection over Union):
衡量模型检测出的区域与实际目标区域的重叠程度。
平均精度(Average Precision,AP):
在目标检测中,AP通常指Precision-Recall曲线下的面积,用于综合评估模型的性能。
mAP(mean Average Precision):
多类别目标检测任务中,各类别的AP的平均值。
漏检率(Miss Rate):
表示模型未能检测到的目标数量占所有实际正样本的比例。
虚警率(False Alarm Rate):
表示模型错误地将负样本预测为正样本的数量占所有负样本的比例。
速度相关指标:
前向传播时间(Inference Time):
模型进行一次前向传播所需的时间。
每秒帧数(Frames Per Second,FPS):
描述模型在单位时间内能够处理的帧数。
1.weights目录
该目录下保存了两个训练时的权重:
last.pt:
“last.pt” 一般指代模型训练过程中最后一个保存的权重文件。在训练过程中,模型的权重可能会定期保存,而 “last.pt” 就是最新的一次保存的模型权重文件。这样的文件通常用于从上一次训练的断点继续训练,或者用于模型的推理和评估。
best.pt:
“best.pt” 则通常指代在验证集或测试集上表现最好的模型权重文件。在训练过程中,会通过监视模型在验证集上的性能,并在性能提升时保存模型的权重文件。“best.pt” 可以被用于得到在验证集上表现最好的模型,以避免模型在训练集上过拟合的问题。
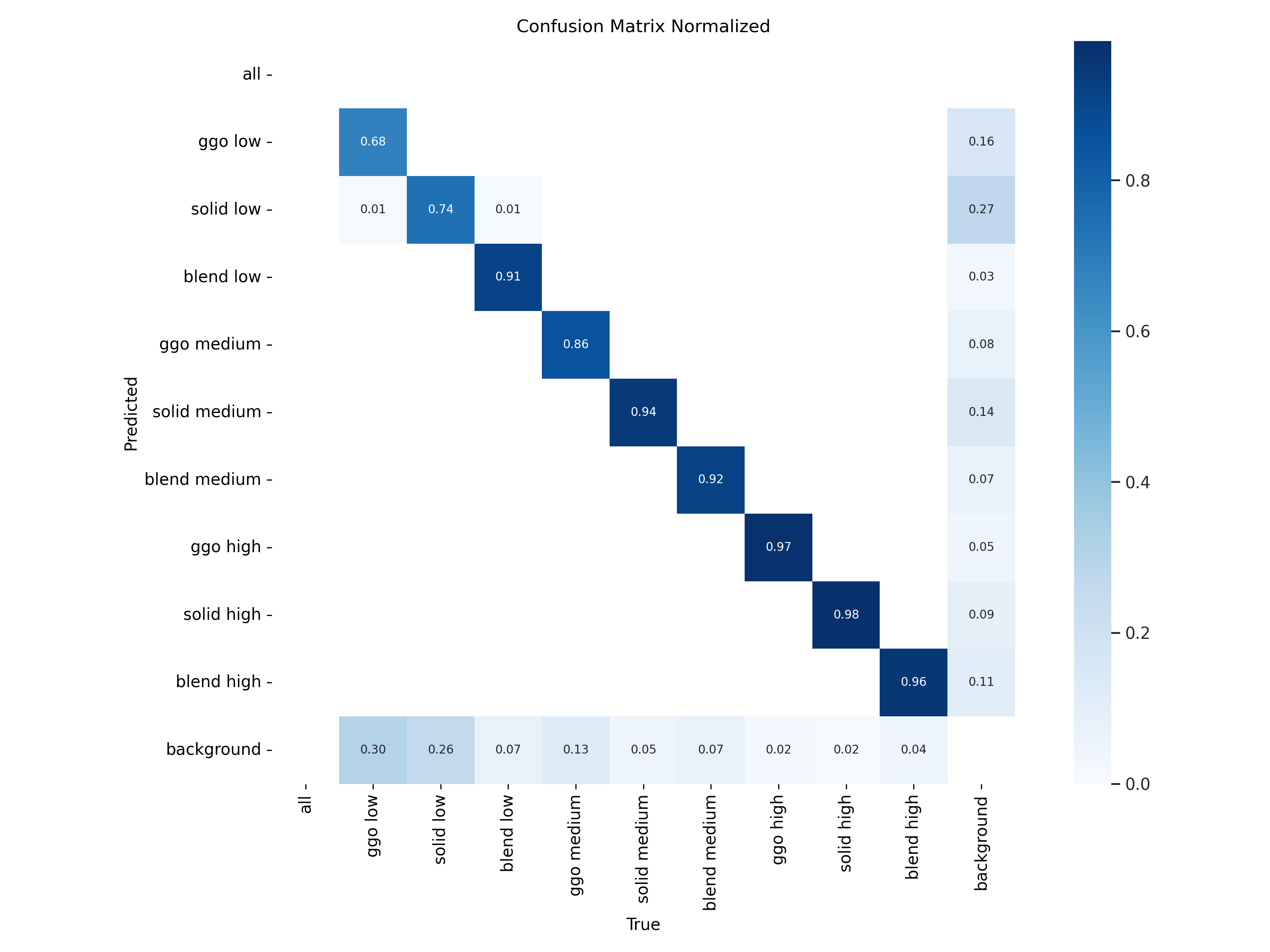
2. 混沌矩阵
confusion_matrix_normalized.png
confusion_matrix.png
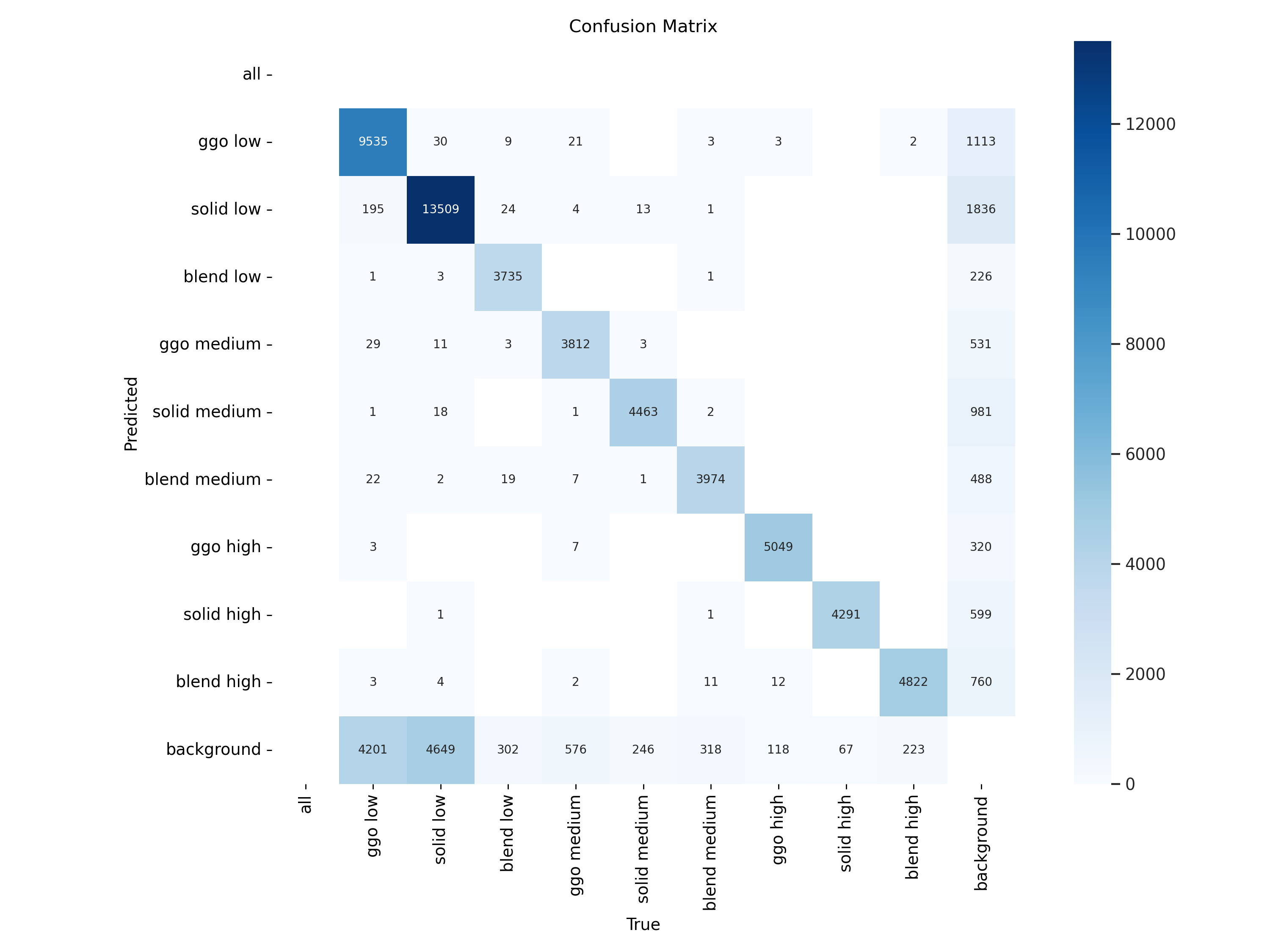
混淆矩阵是对分类问题预测结果的总结,通过计数值汇总正确和不正确预测的数量,并按每个类别进行细分,展示了分类模型在进行预测时对哪些部分产生混淆。该矩阵以行表示预测的类别(y轴),列表示真实的类别(x轴),具体内容如下:
| Predicted 0 | Predicted 1 | ------------|---------------|---------------| Actual 0 | TN | FP | ------------|---------------|---------------| Actual 1 | FN | TP |
其中:
- TP(True Positive)表示将正类预测为正类的数量,即正确预测的正类样本数。
- FN(False Negative)表示将正类预测为负类的数量,即错误预测的正类样本数。
- FP(False Positive)表示将负类预测为正类的数量,即错误预测的负类样本数。
- TN(True Negative)表示将负类预测为负类的数量,即正确预测的负类样本数。
混淆矩阵的使用有助于直观了解分类模型的错误类型,特别是了解模型是否将两个不同的类别混淆,将一个类别错误地预测为另一个类别。这种详细的分析有助于克服仅使用分类准确率带来的局限性。
精确率(Precision)和召回率(Recall)是常用于评估分类模型性能的指标,其计算方法如下:
精确率(Precision):
公式:Precision = TP / (TP + FP)
解释:精确率是指在所有被模型预测为正例(Positive)的样本中,实际为正例的比例。它衡量了模型在正例预测中的准确性。
召回率(Recall):
公式:Recall = TP / (TP + FN)
解释:召回率是指在所有实际为正例的样本中,模型成功预测为正例的比例。它衡量了模型对正例的识别能力。
3. F1 曲线的图示
F1_curve.png
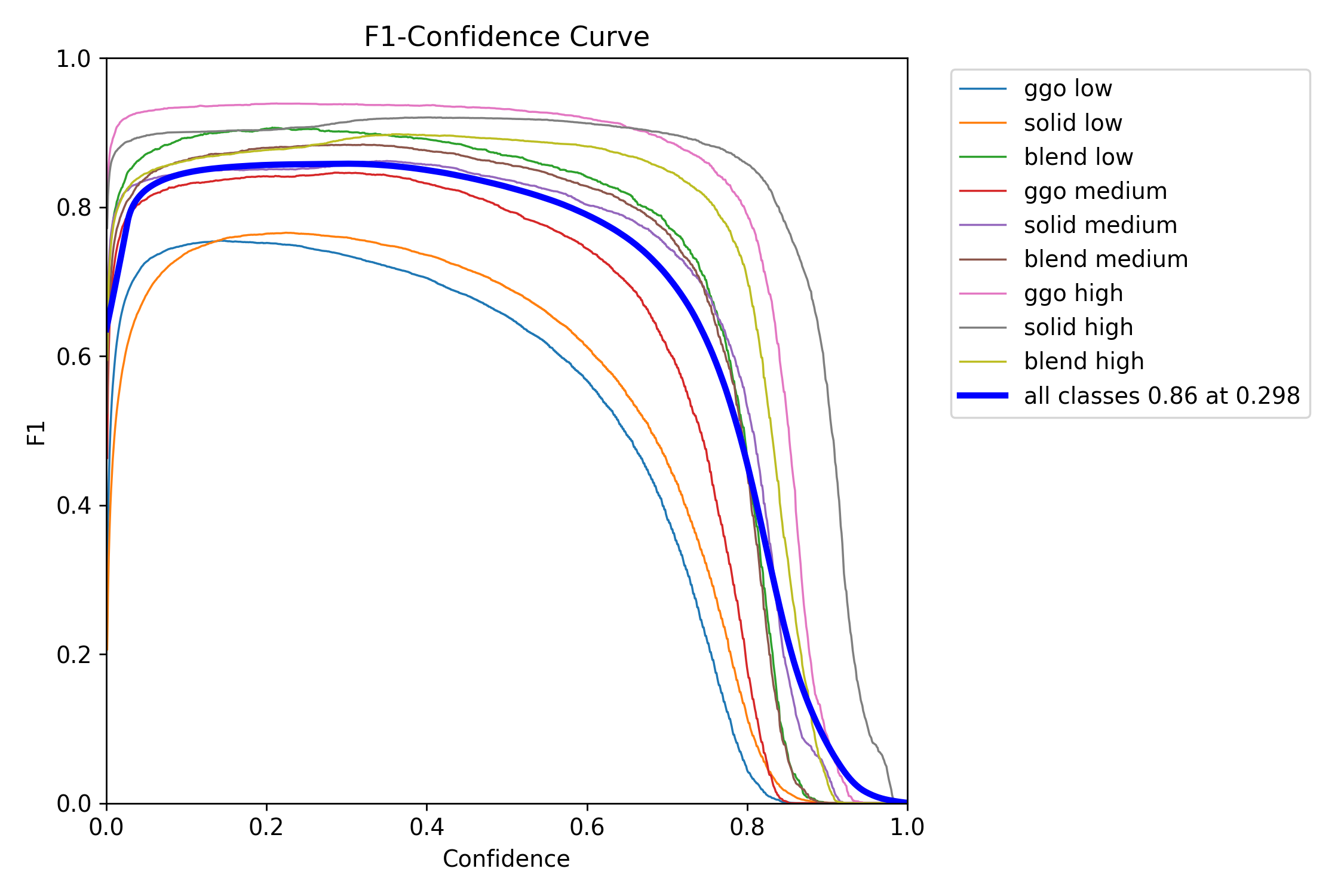
为了能够评价不同算法的优劣,在Precision和Recall的基础上提出了F1值的概念,来对Precision和Recall进行整体评价。F1的定义如下:

F1曲线是一种多分类问题中常用的性能评估工具,尤其在竞赛中得到广泛应用。它基于F1分数,这是精确率和召回率的调和平均数,取值范围介于0和1之间。1代表最佳性能,而0代表最差性能。
通常情况下,通过调整置信度阈值(判定为某一类的概率阈值),可以观察到F1曲线在不同阈值下的变化。在阈值较低时,模型可能将许多置信度较低的样本判定为真,从而提高召回率但降低精确率。而在阈值较高时,只有置信度很高的样本才被判定为真,使得模型的类别判定更为准确,进而提高精确率。
理想状态下,F1曲线显示在置信度为0.4-0.6的区间内取得了较好的F1分数。表明在这个范围内,模型在平衡精确率和召回率方面表现较为理想。
4. 标签图
labels.jpg
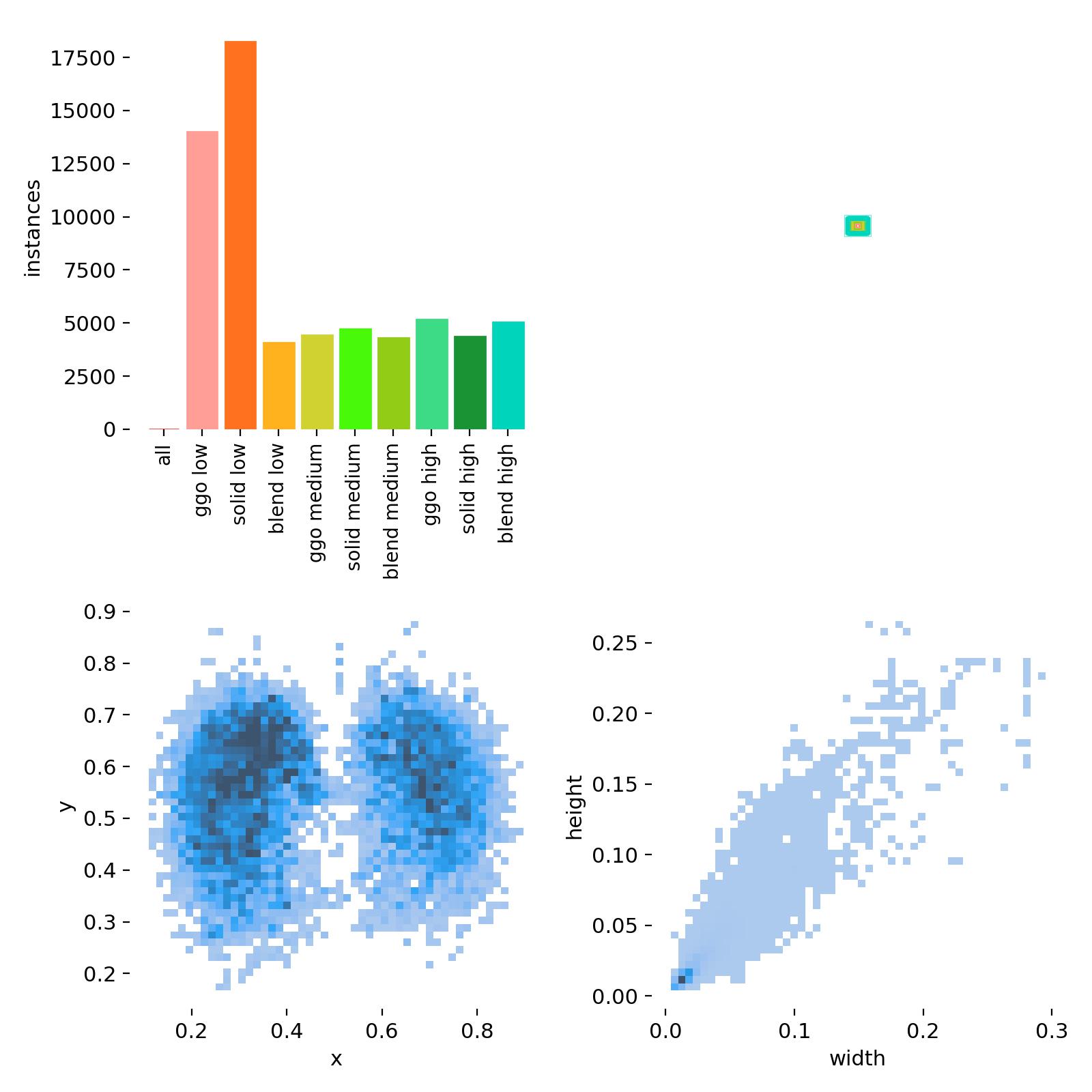
从左往右按顺序排列:
宫格1:训练集的数据量,显示每个类别包含的样本数量。
宫格2:框的尺寸和数量,展示了训练集中边界框的大小分布以及相应数量。
宫格3:中心点相对于整幅图的位置,描述了边界框中心点在图像中的位置分布情况。
宫格4:图中目标相对于整幅图的高宽比例,反映了训练集中目标高宽比例的分布状况。
5.颜色矩阵图
labels_correlogram.jpg
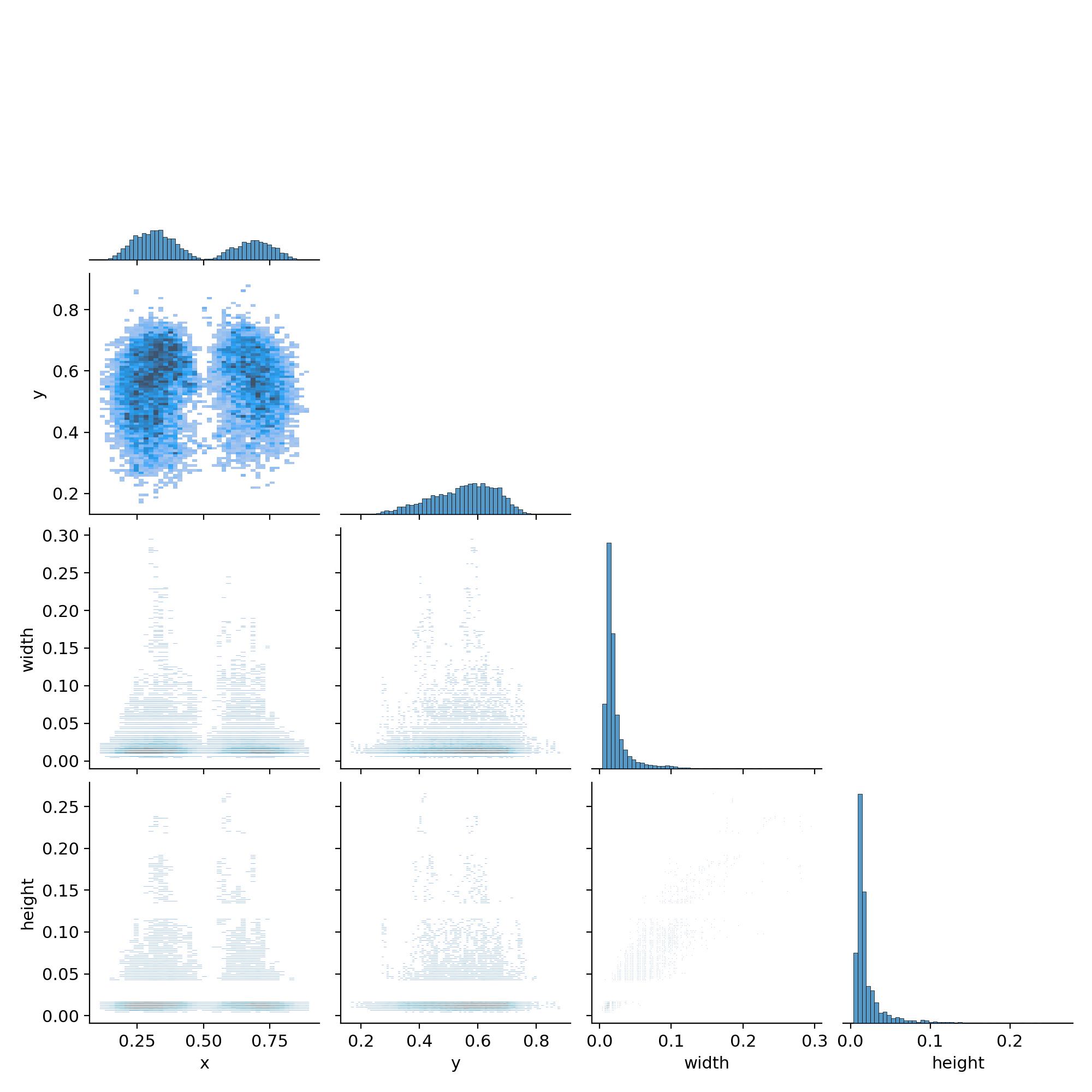
展示了目标检测算法在训练过程中对标签之间相关性的建模情况。每个矩阵单元代表模型训练时使用的标签,而单元格的颜色深浅反映了对应标签之间的相关性。
- 深色单元格表示模型更强烈地学习了这两个标签之间的关联性。
浅色单元格则表示相关性较弱。 - 对角线上的颜色代表每个标签自身的相关性,通常是最深的,因为模型更容易学习标签与自身的关系。
可以直观识别到哪些标签之间存在较强的相关性,这对于优化训练和预测效果至关重要。如果发现某些标签之间的相关性过强,可能需要考虑合并它们,以简化模型并提高效率。最上面的图(0,0)至(3,3)分别表示中心点横坐标x、中心点纵坐标y、框的宽和框的高的分布情况。
6.单一类准确率
P_curve.png
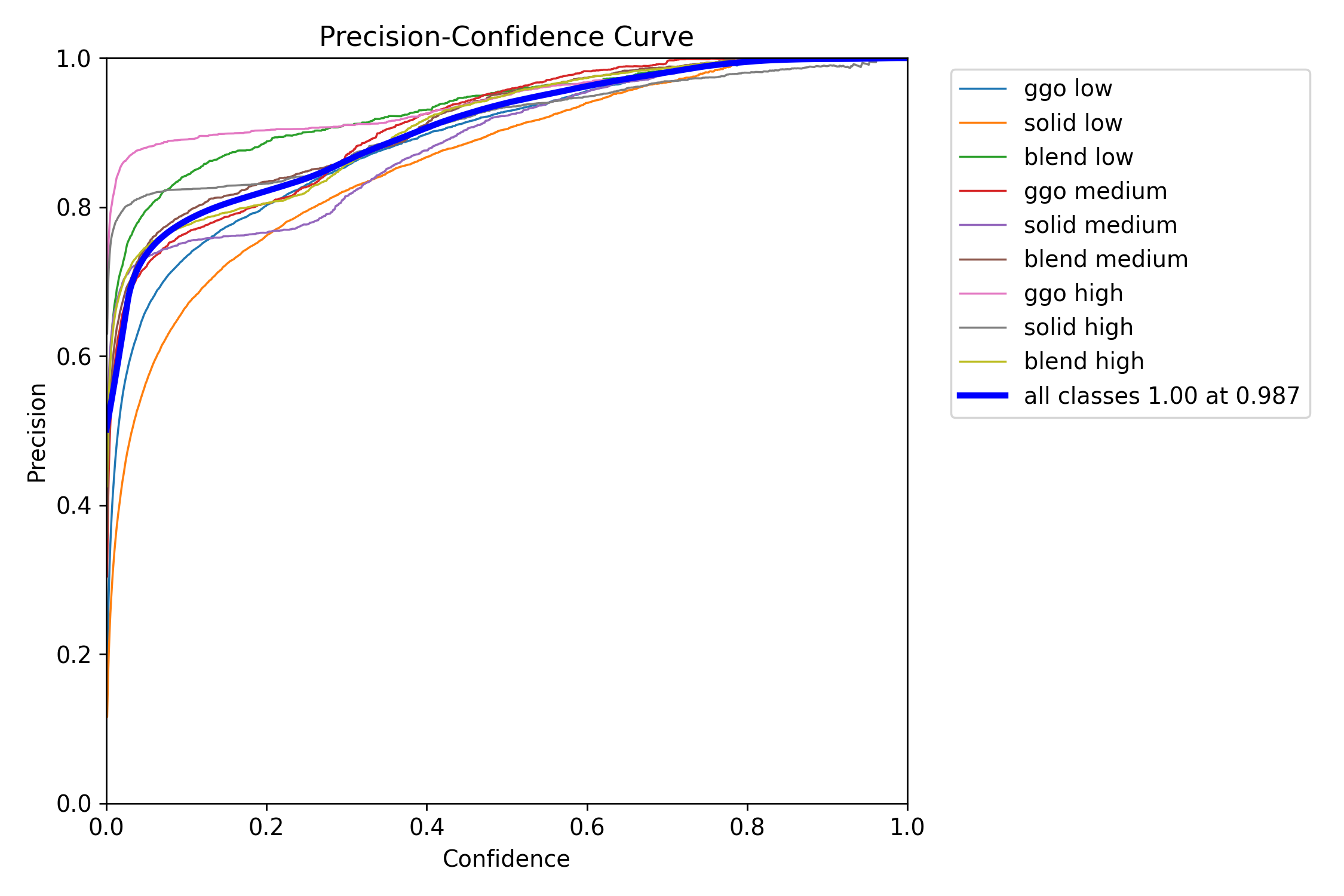
PCC图的横坐标表示检测器的置信度,纵坐标表示精度(或召回率)。曲线的形状和位置反映了检测器在不同信心水平下的性能。
在PCC图中,当曲线向上并向左弯曲时,表示在较低置信度下仍能保持较高的精度,说明检测器在高召回率的同时能够保持低误报率,即对目标的识别准确性较高。
相反,当曲线向下并向右弯曲时,说明在较高置信度下才能获得较高的精度,这可能导致漏检率的增加,表示检测器的性能较差。
因此,PCC图对于评估检测器在不同信心水平下的表现提供了有用的信息。在图中,曲线向上并向左弯曲是期望的效果,而曲线向下并向右弯曲则表示改进的空间。
7.单一类召回率
R_curve.png
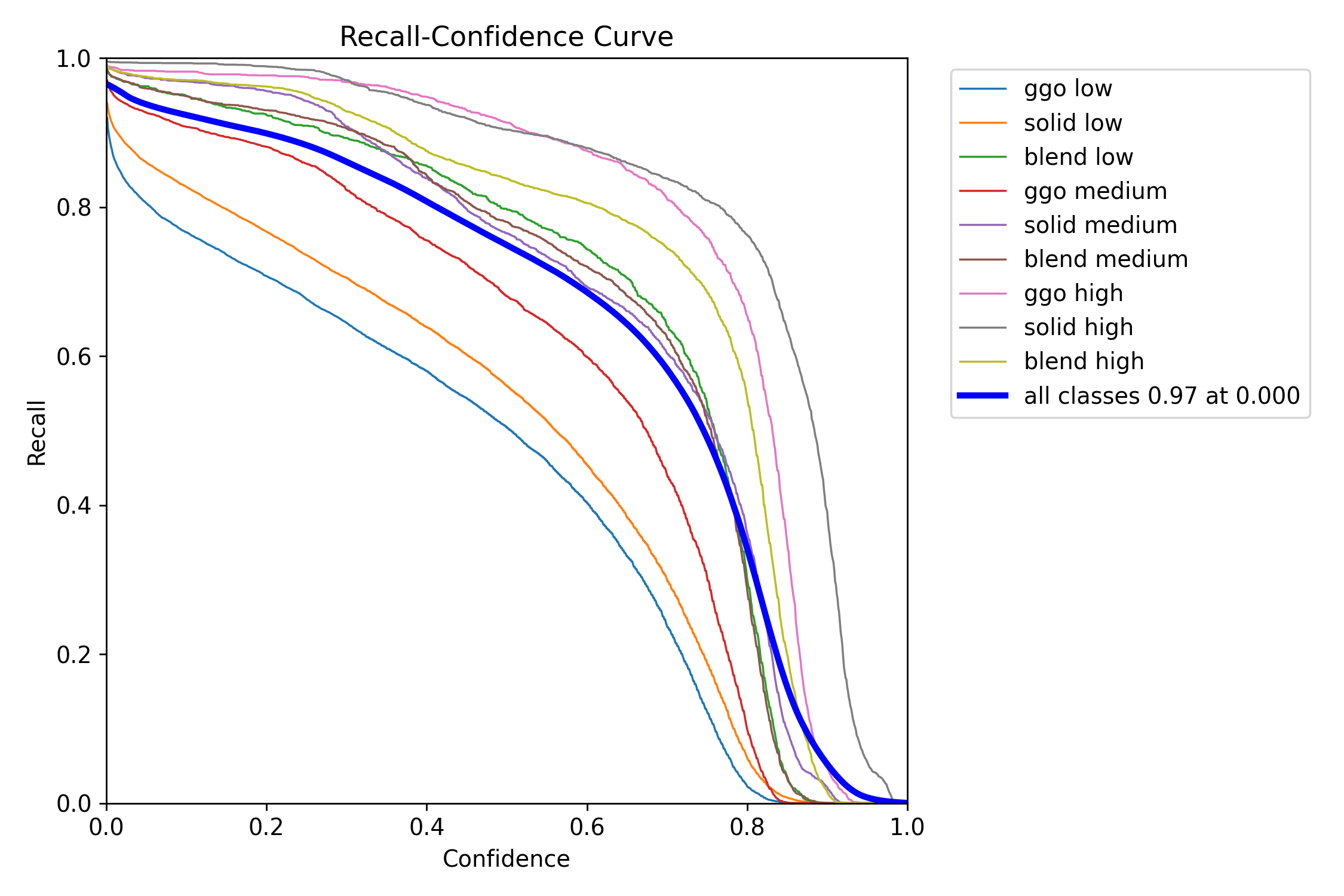
在理想情况下,希望算法在保持高召回率的同时能够保持较高的精度。
在RCC图中,当曲线在较高置信度水平下呈现较高召回率时,说明算法在目标检测时能够准确地预测目标的存在,并在过滤掉低置信度的预测框后依然能够维持高召回率。这反映了算法在目标检测任务中的良好性能。
值得注意的是,RCC图中曲线的斜率越陡峭,表示在过滤掉低置信度的预测框后,获得的召回率提升越大,从而提高模型的检测性能。
在图表中,曲线越接近右上角,表示模型性能越好。当曲线靠近图表的右上角时,说明模型在保持高召回率的同时能够维持较高的精度。因此,RCC图可用于全面评估模型性能,帮助找到平衡模型召回率和精度的合适阈值。
8.精确率和召回率的关系图
PR_curve.png
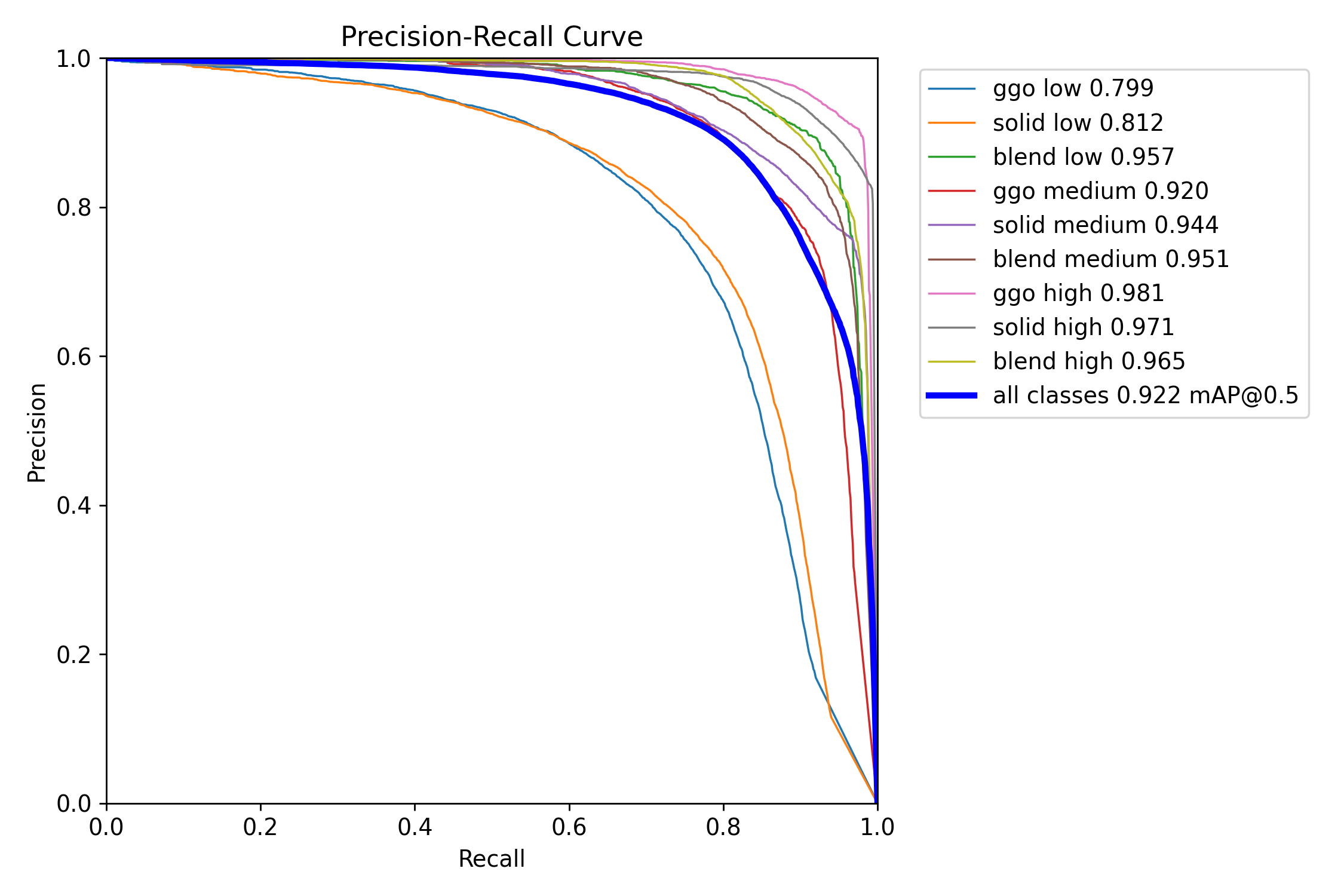
PR_curve是精确率(Precision)和召回率(Recall)之间的关系。精确率表示预测为正例的样本中真正为正例的比例,而召回率表示真正为正例的样本中被正确预测为正例的比例。
在PR Curve中,横坐标表示召回率,纵坐标表示精确率。通常情况下,当召回率升高时,精确率会降低,反之亦然。PR Curve反映了这种取舍关系。曲线越靠近右上角,表示模型在预测时能够同时保证高的精确率和高的召回率,即预测结果较为准确。相反,曲线越靠近左下角,表示模型在预测时难以同时保证高的精确率和高的召回率,即预测结果较为不准确。
通常,PR Curve与ROC Curve一同使用,以更全面地评估分类模型的性能。 PR Curve提供了对模型在不同任务下性能表现的更详细的洞察。
9. 训练过程的记录
results.png
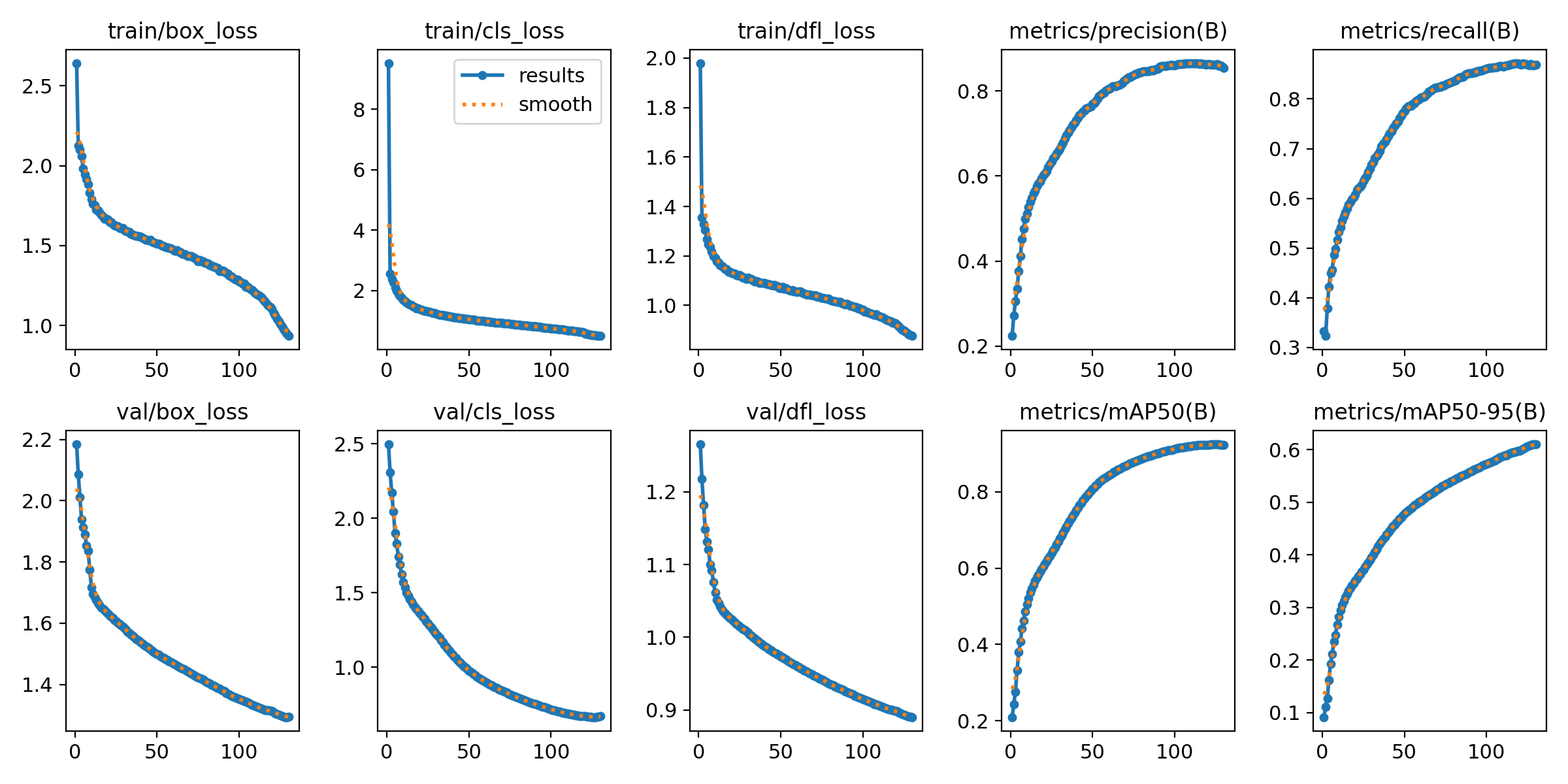
| box_loss | bounding_box与GroundTruth之间的差异 |
| obj_loss | GroundTruth的检测丢失 |
| cls_loss | GroundTruth对应的bounding_box分类错误 |
| precision | 精确率=TP/TP+FP |
| recall | 召回率=TP/TP+FN |
损失函数在目标检测任务中扮演关键角色,它用于衡量模型的预测值与真实值之间的差异,直接影响模型性能。以下是一些与目标检测相关的损失函数和性能评价指标的解释:
定位损失(box_loss):
定义: 衡量预测框与标注框之间的误差,通常使用 GIoU(Generalized Intersection over Union)来度量,其值越小表示定位越准确。
目的: 通过最小化定位损失,使模型能够准确地定位目标。
置信度损失(obj_loss):
定义: 计算网络对目标的置信度,通常使用二元交叉熵损失函数,其值越小表示模型判断目标的能力越准确。
目的: 通过最小化置信度损失,使模型能够准确判断目标是否存在。
分类损失(cls_loss):
定义: 计算锚框对应的分类是否正确,通常使用交叉熵损失函数,其值越小表示分类越准确。
目的: 通过最小化分类损失,使模型能够准确分类目标。
Precision(精度):
定义: 正确预测为正类别的样本数量占所有预测为正类别的样本数量的比例。
目的: 衡量模型在所有预测为正例的样本中有多少是正确的。
Recall(召回率):
定义: 正确预测为正类别的样本数量占所有真实正类别的样本数量的比例。
目的: 衡量模型能够找出真实正例的能力。
mAP(平均精度):
定义: 使用 Precision-Recall 曲线计算的面积,mAP@[.5:.95] 表示在不同 IoU 阈值下的平均 mAP。
目的: 综合考虑了模型在不同精度和召回率条件下的性能,是目标检测任务中常用的评价指标。
在训练过程中,通常需要关注精度和召回率的波动情况,以及 [email protected] 和 mAP@[.5:.95] 评估训练结果。这些指标可以提供关于模型性能和泛化能力的有用信息。
10.args.yaml文件
args.yaml这个文件通常包含了模型训练时使用的配置参数。它详细记录了训练过程中使用的所有设置,如学习率、批大小、训练轮数等。这个文件的目的是为了提供一个清晰的训练配置概览,使得训练过程可以被复现或调整。
训练时的超参数:
task: detect mode: train model: yolov8s.pt data: coco8.yaml epochs: 150 patience: 50 batch: 8 imgsz: 640 save: true save_period: -1 cache: false device: 0 workers: 0 project: null name: train exist_ok: false pretrained: true optimizer: auto verbose: true seed: 0 deterministic: true single_cls: false rect: false cos_lr: false close_mosaic: 10 resume: false amp: true fraction: 1.0 profile: false freeze: null overlap_mask: true mask_ratio: 4 dropout: 0.0 val: true split: val save_json: false save_hybrid: false conf: null iou: 0.7 max_det: 300 half: false dnn: false plots: true source: null show: false save_txt: false save_conf: false save_crop: false show_labels: true show_conf: true vid_stride: 1 stream_buffer: false line_width: null visualize: false augment: false agnostic_nms: false classes: null retina_masks: false boxes: true format: torchscript keras: false optimize: false int8: false dynamic: false simplify: false opset: null workspace: 4 nms: false lr0: 0.01 lrf: 0.01 momentum: 0.937 weight_decay: 0.0005 warmup_epochs: 3.0 warmup_momentum: 0.8 warmup_bias_lr: 0.1 box: 7.5 cls: 0.5 dfl: 1.5 pose: 12.0 kobj: 1.0 label_smoothing: 0.0 nbs: 64 hsv_h: 0.015 hsv_s: 0.7 hsv_v: 0.4 degrees: 0.0 translate: 0.1 scale: 0.5 shear: 0.0 perspective: 0.0 flipud: 0.0 fliplr: 0.5 mosaic: 1.0 mixup: 0.0 copy_paste: 0.0 cfg: null tracker: botsort.yaml save_dir: runsdetecttrain
12.各项损失、精确度、mAP值、lr 等信息
模型训练时每次迭代结果:
results.csv

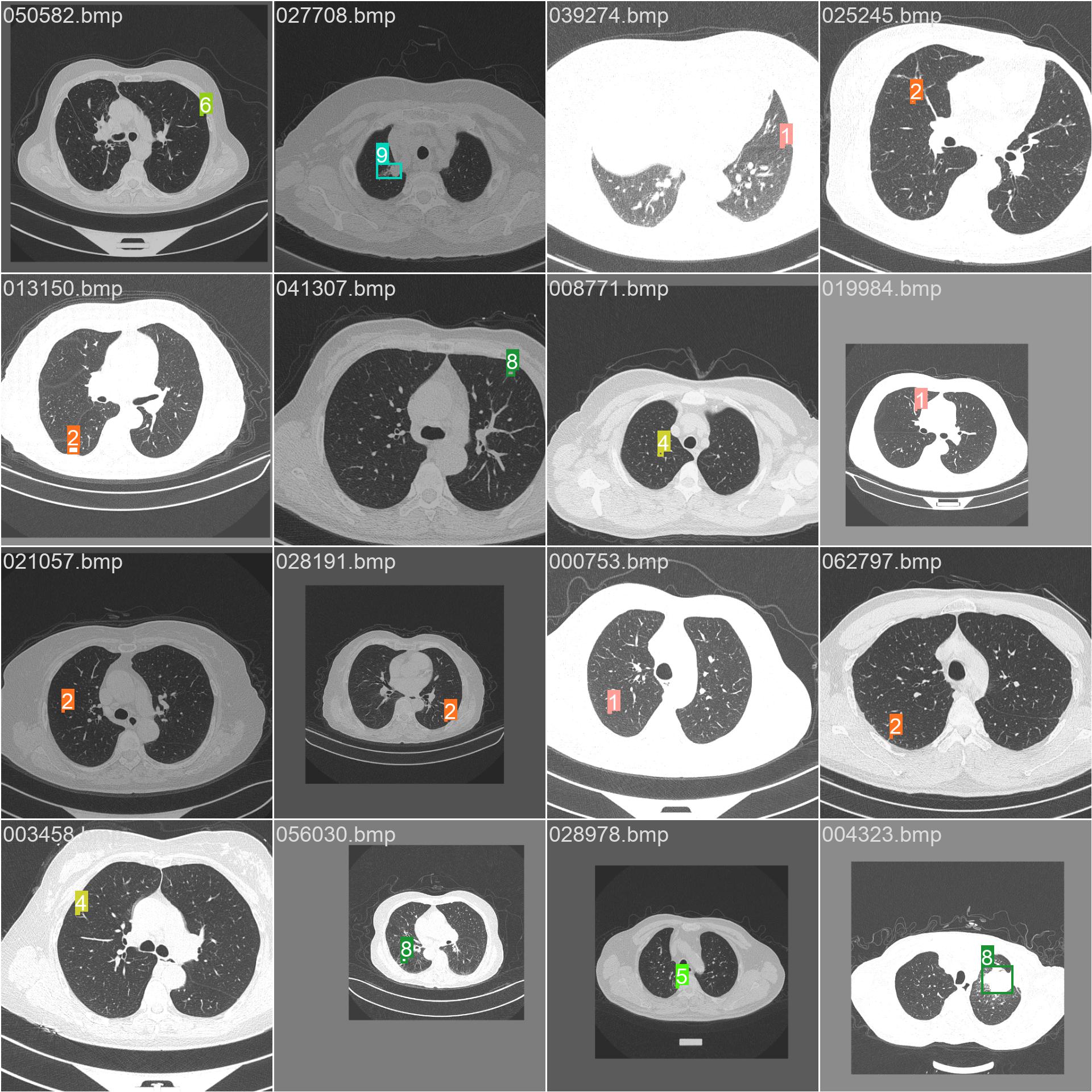
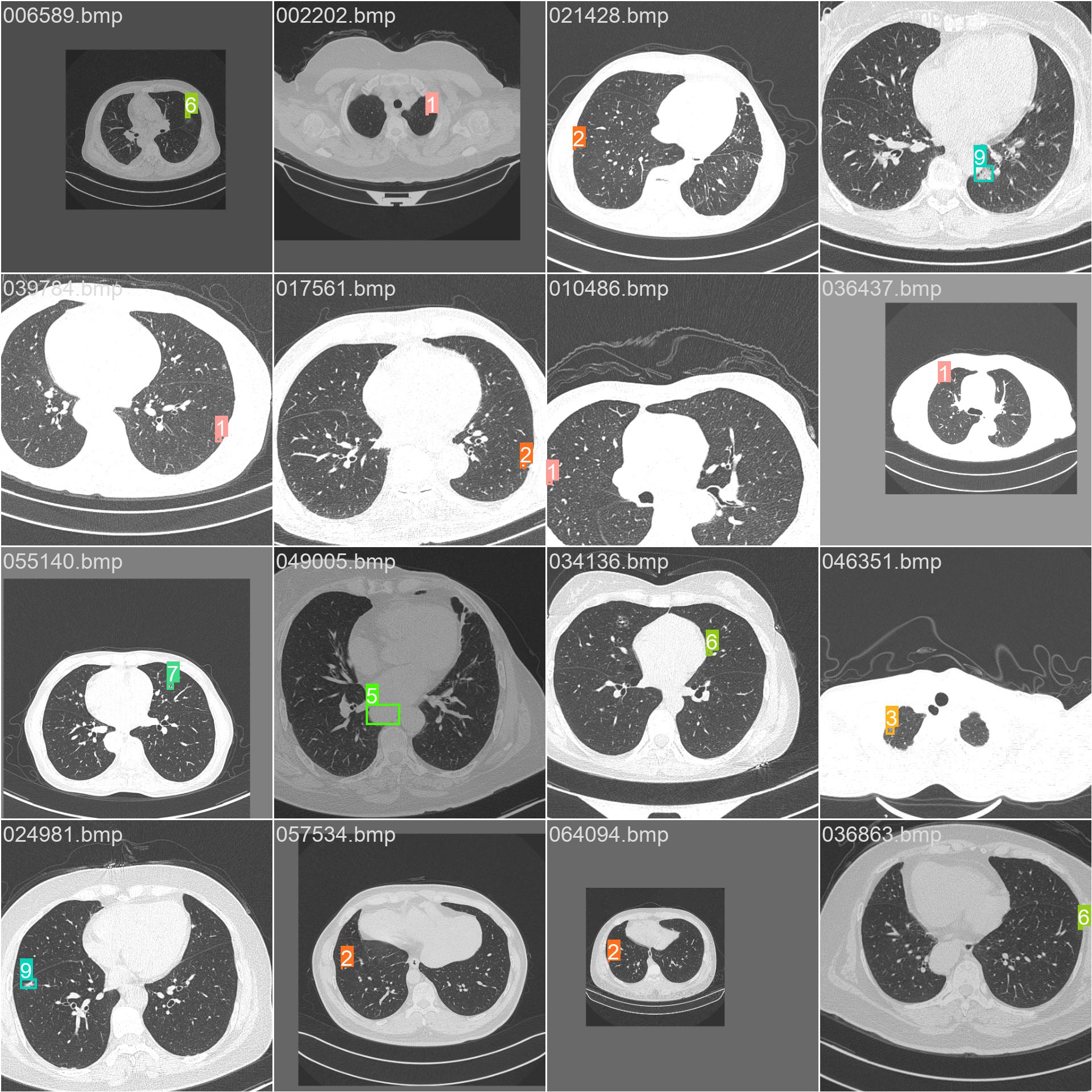
13.马赛克和标签
train_batch0.jpg
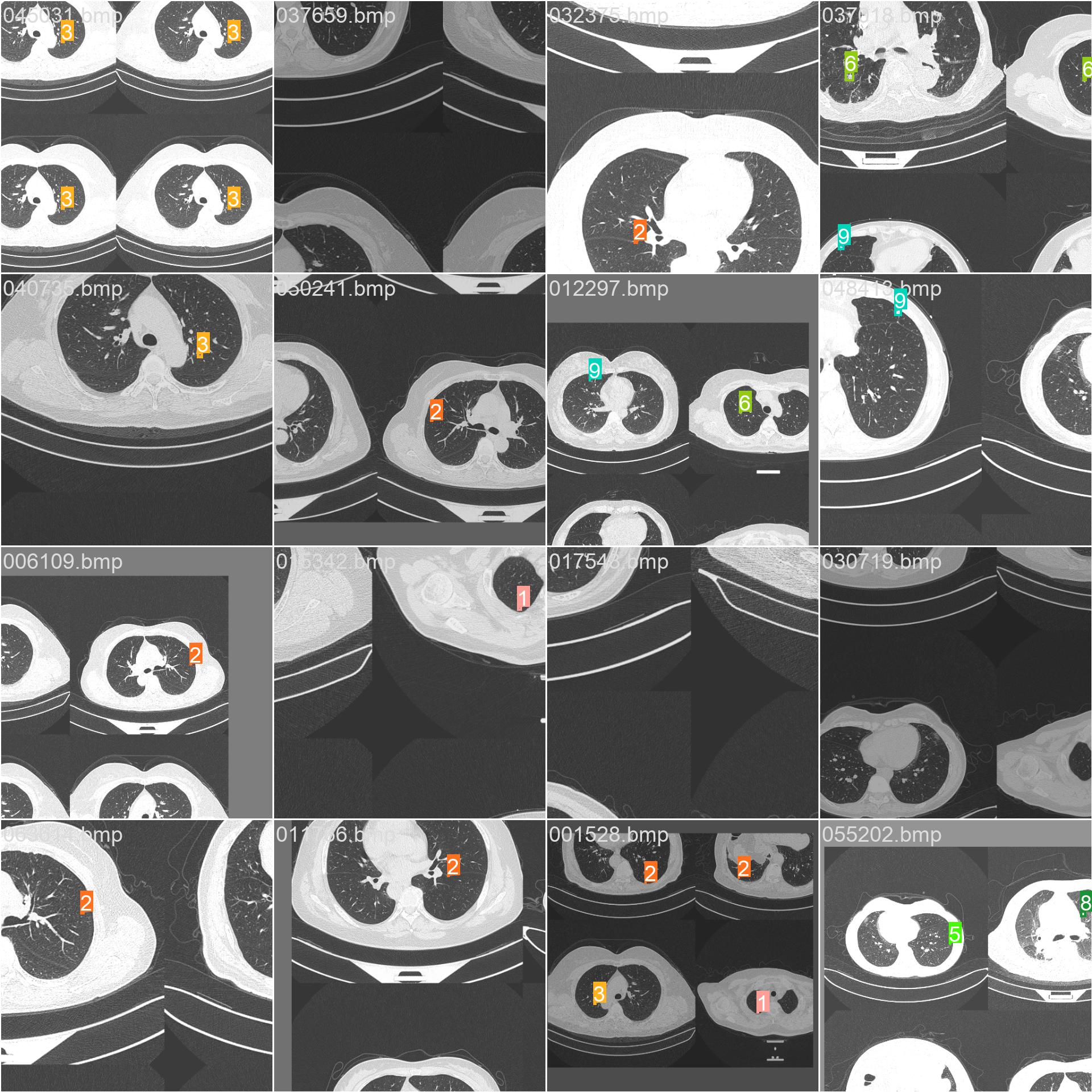
train_batch1.jpg
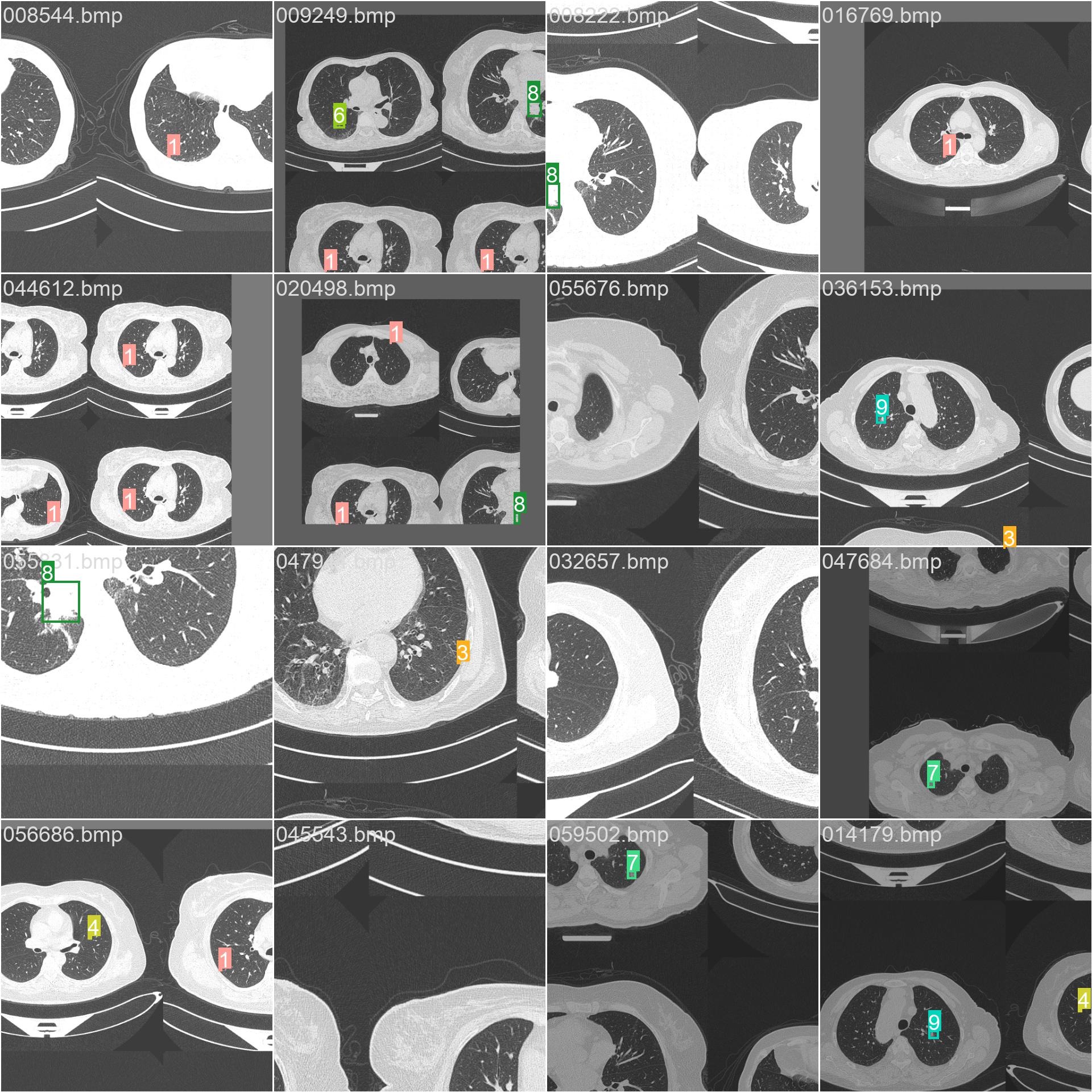
train_batch2.jpg
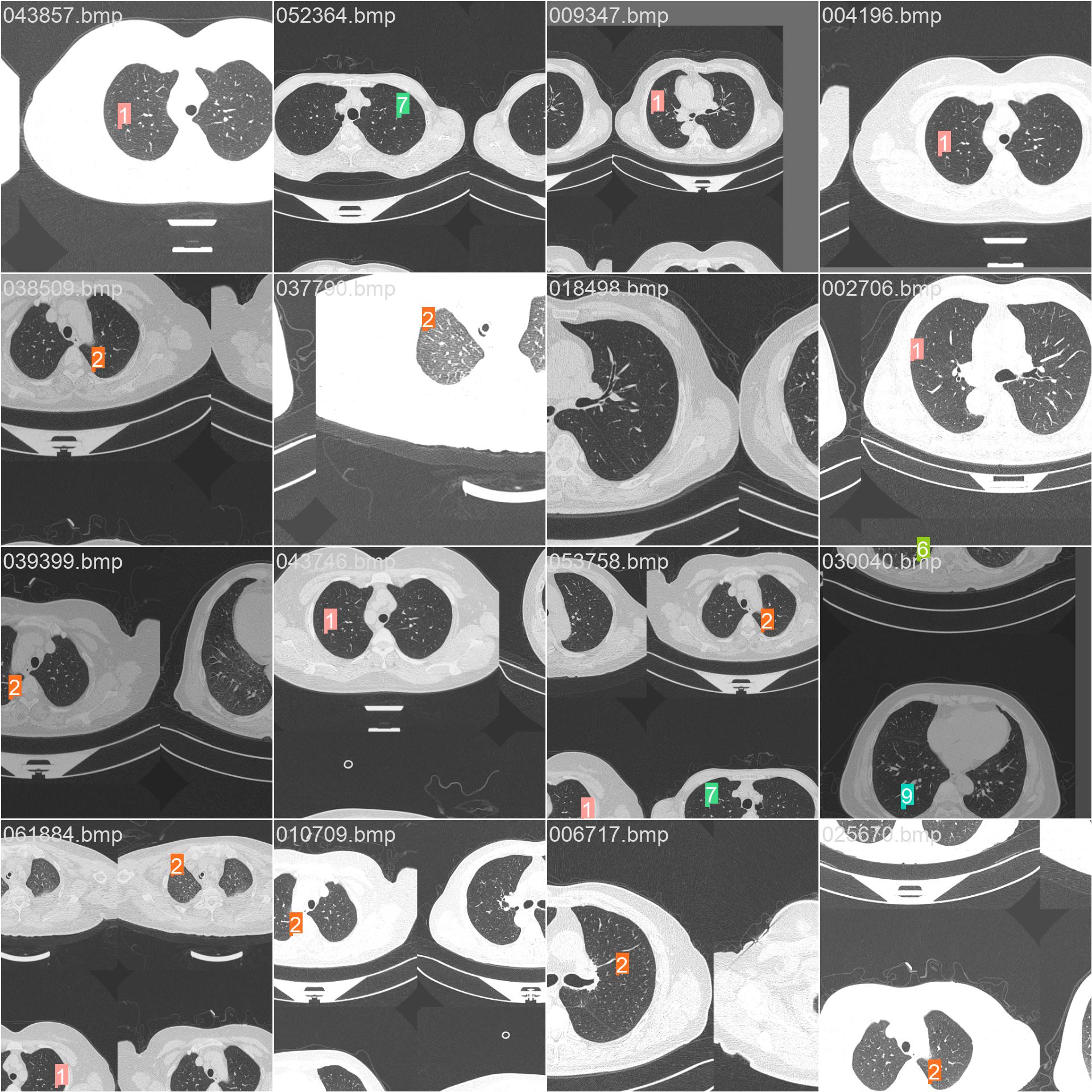
train_batch482760.jpg
train_batch482761.jpg
train_batch482762.jpg
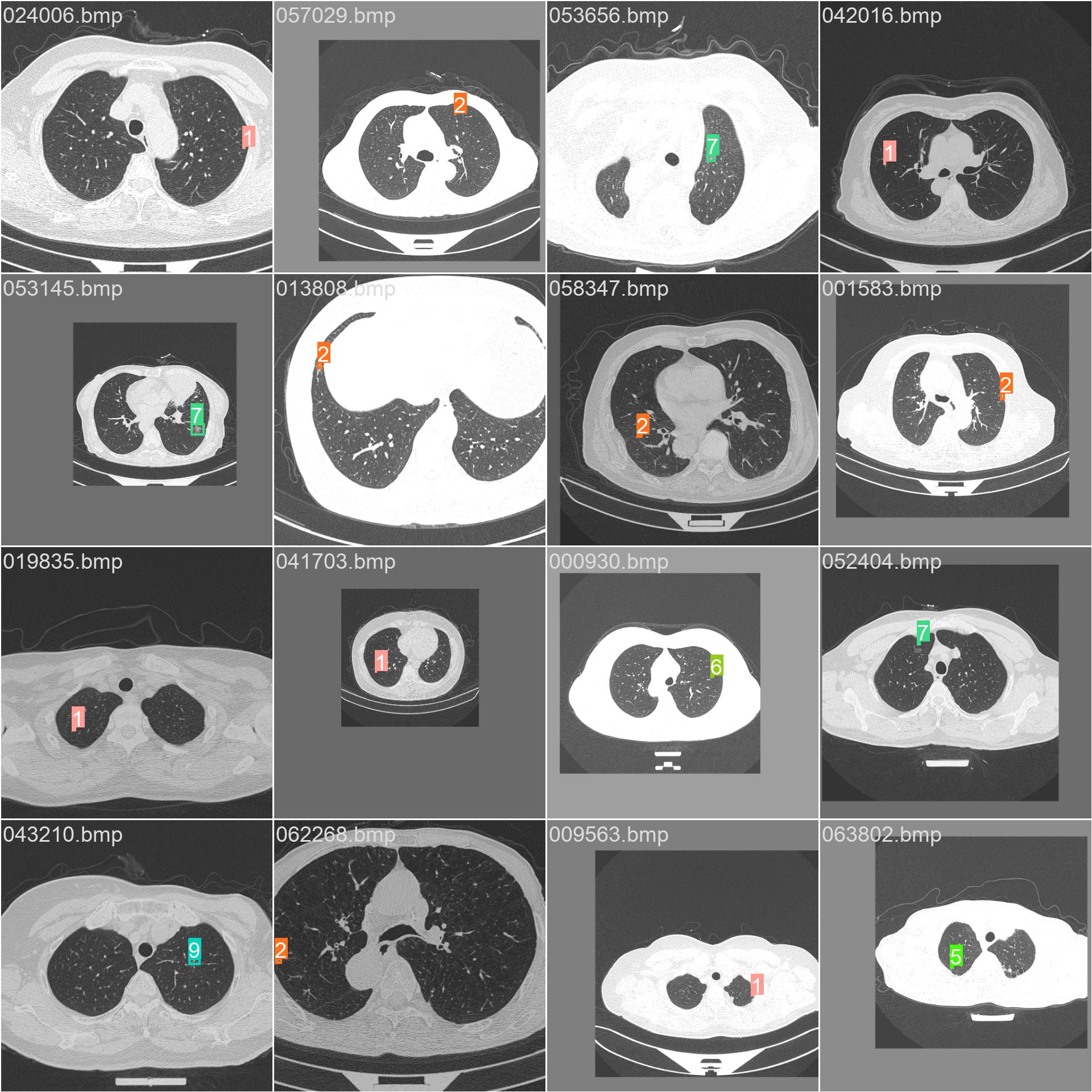
14.测试集的标签和预测结果
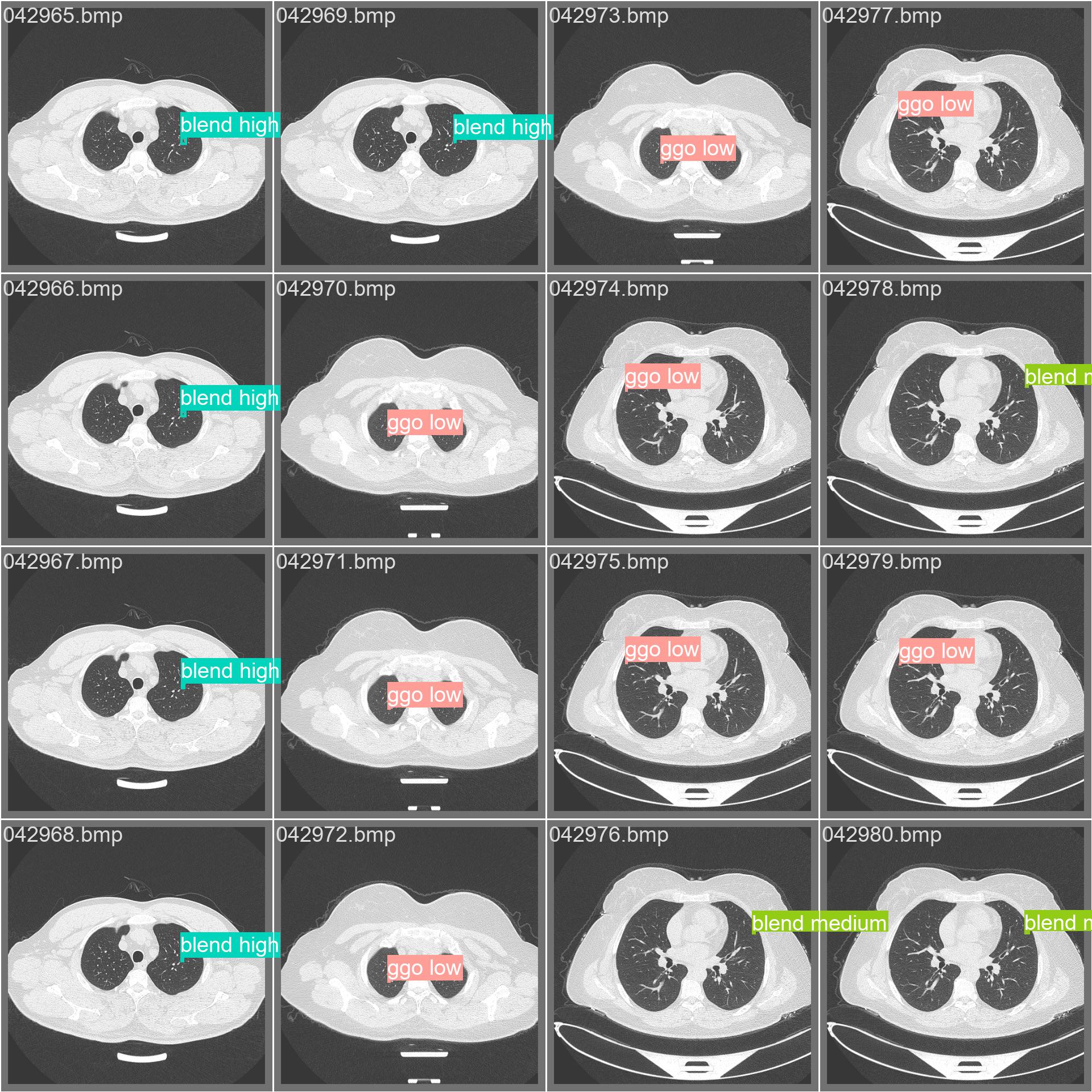
val_batch0_labels.jpg
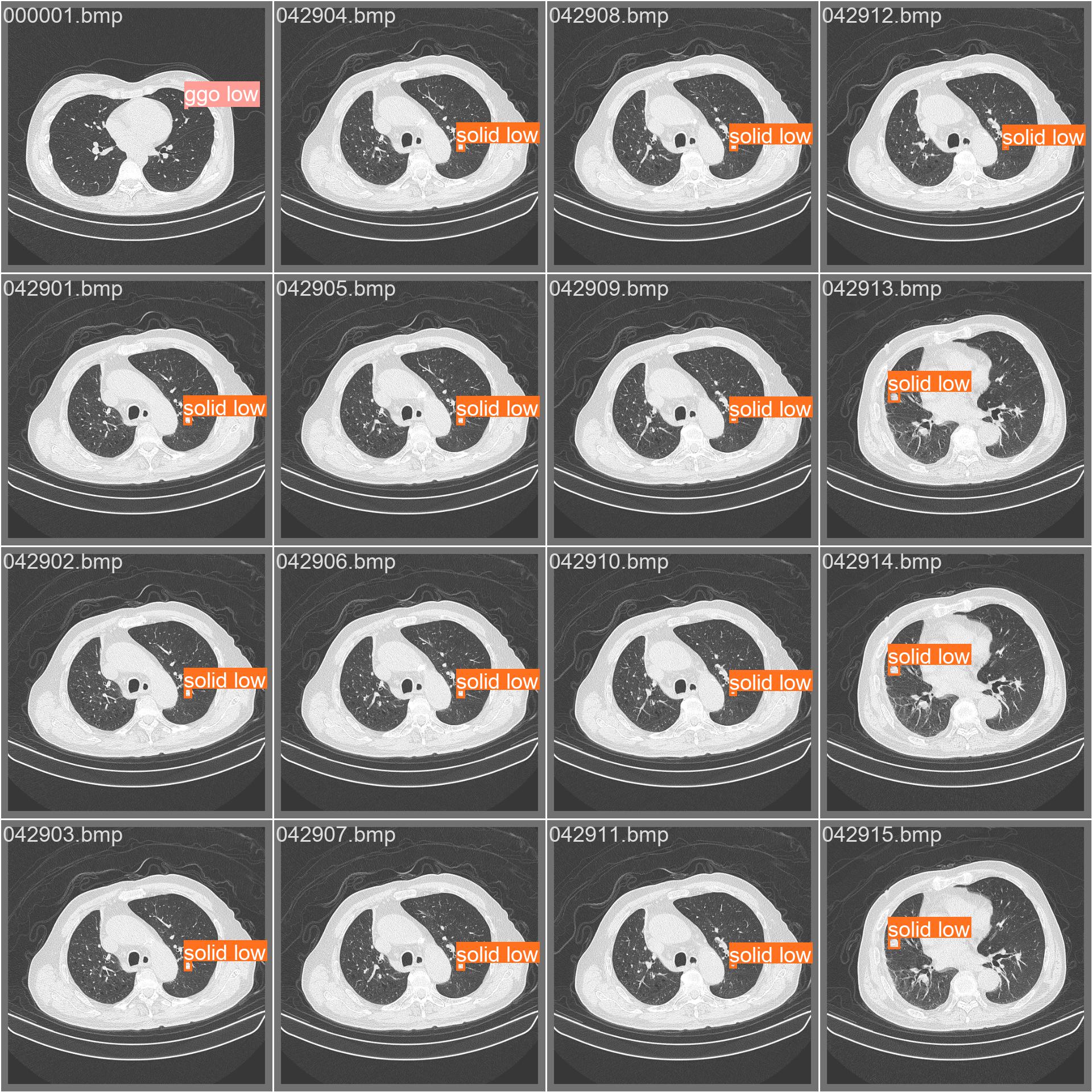
val_batch1_labels.jpg
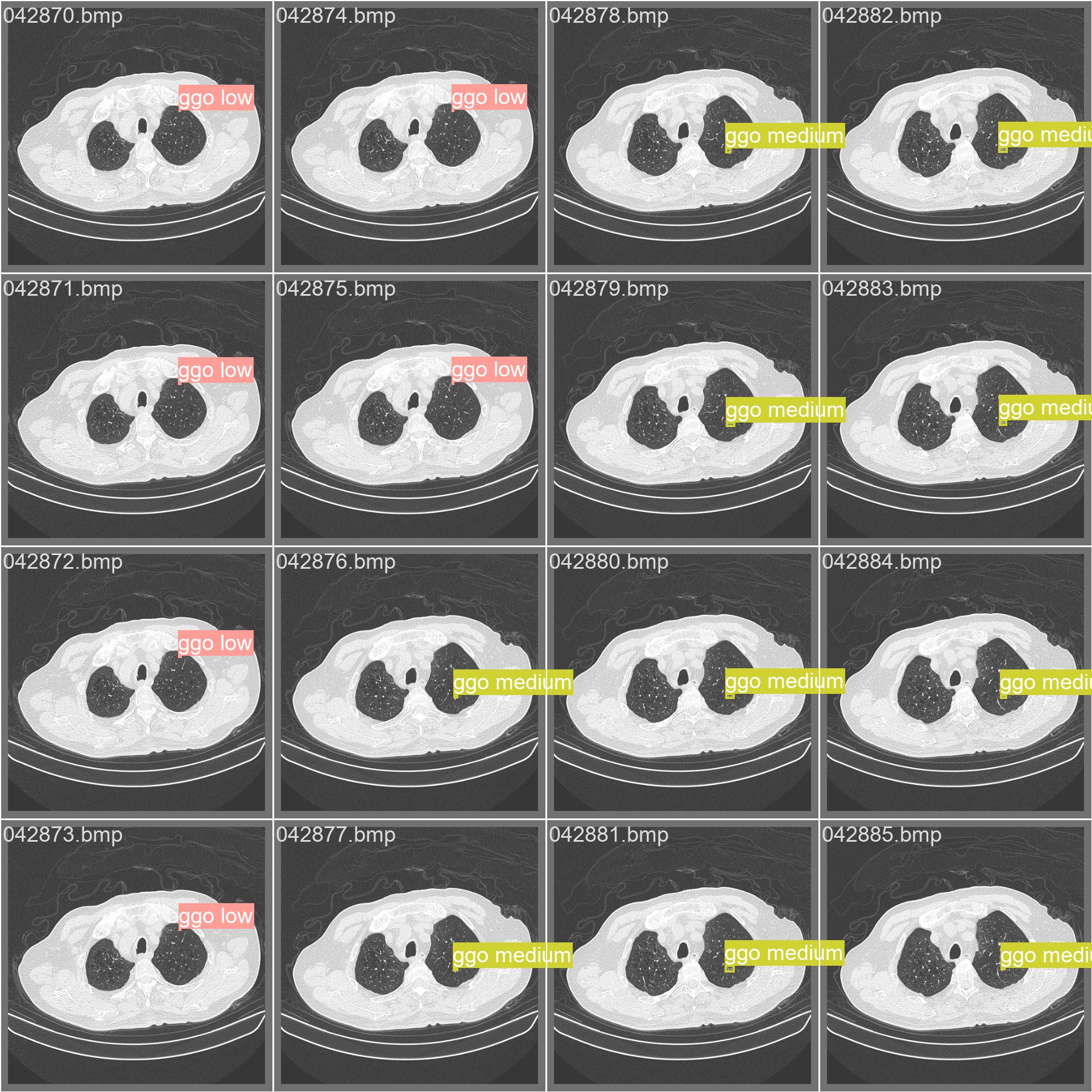
val_batch2_labels.jpg
val_batch0_pred.jpg
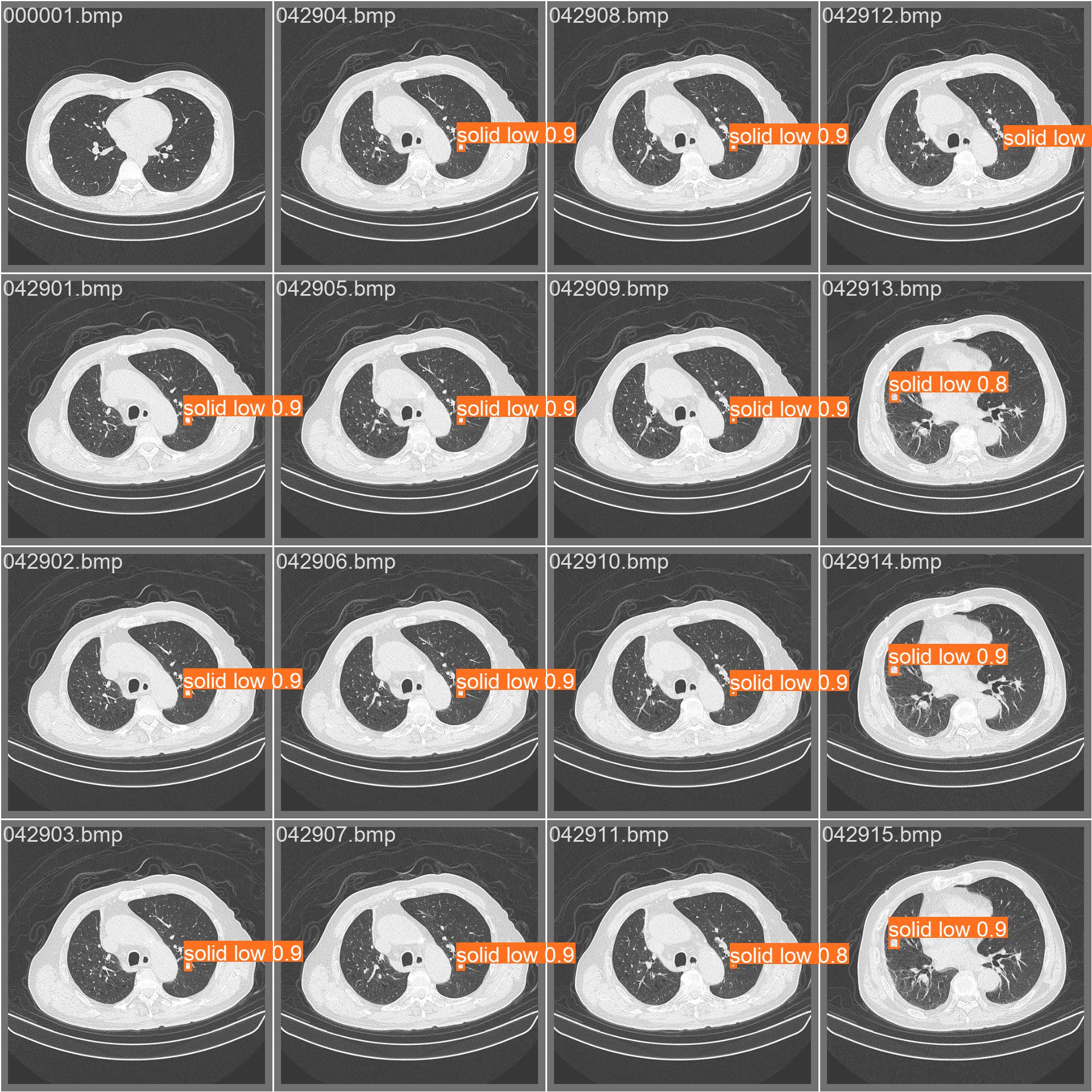
val_batch1_pred.jpg
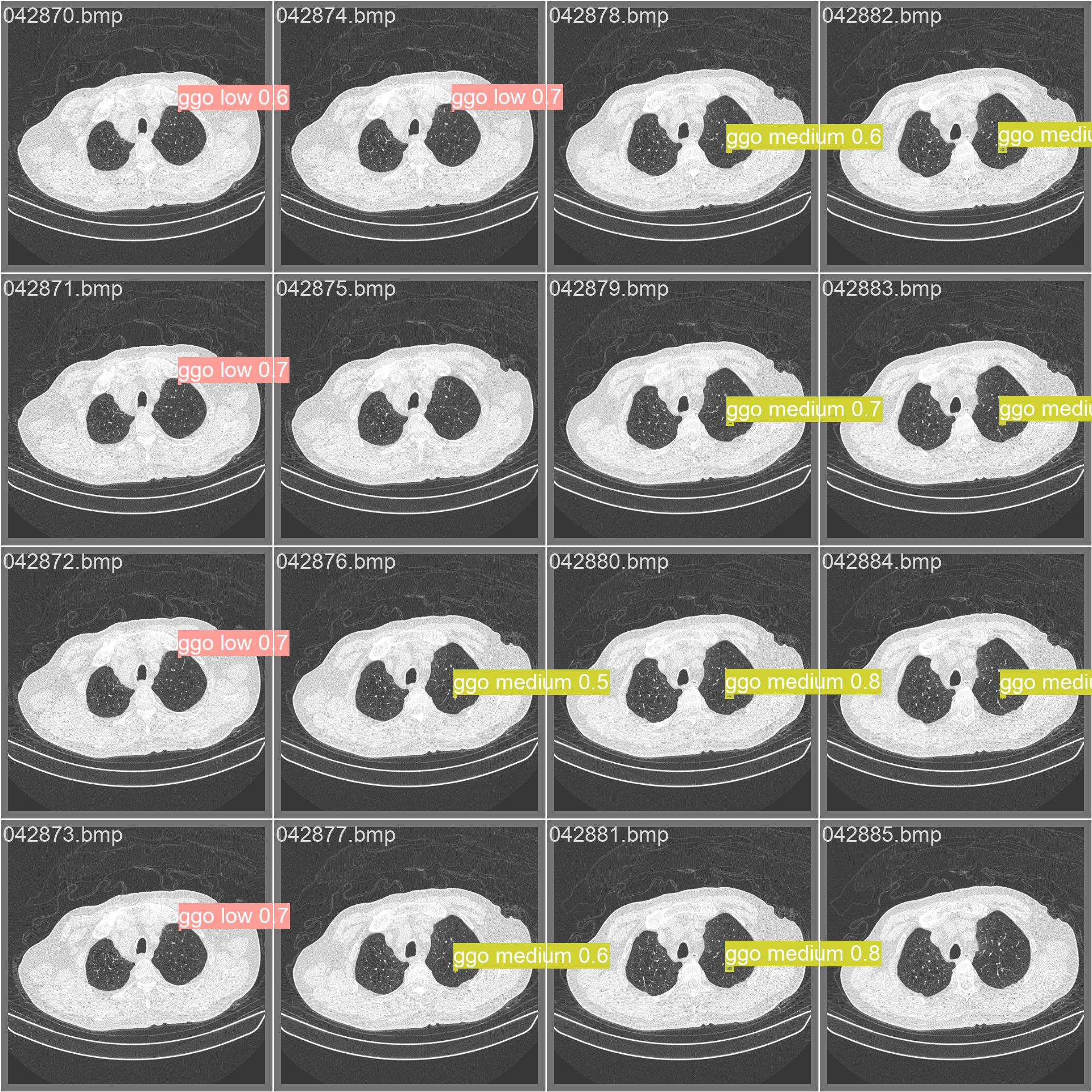
val_batch2_pred.jpg
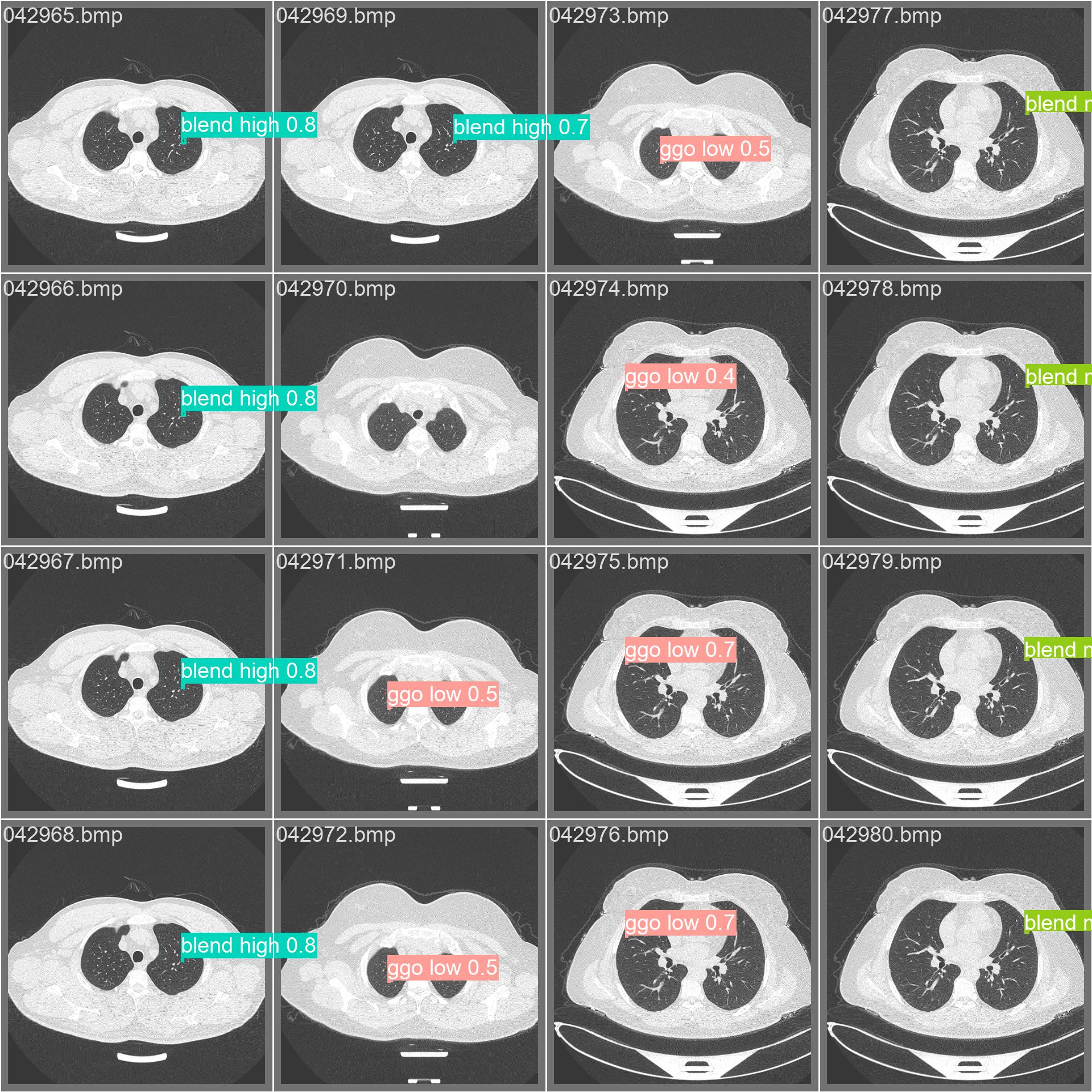
val_batchx_labels:验证集第N轮的实际标签
val_batchx_pred:验证集第N轮的预测标签