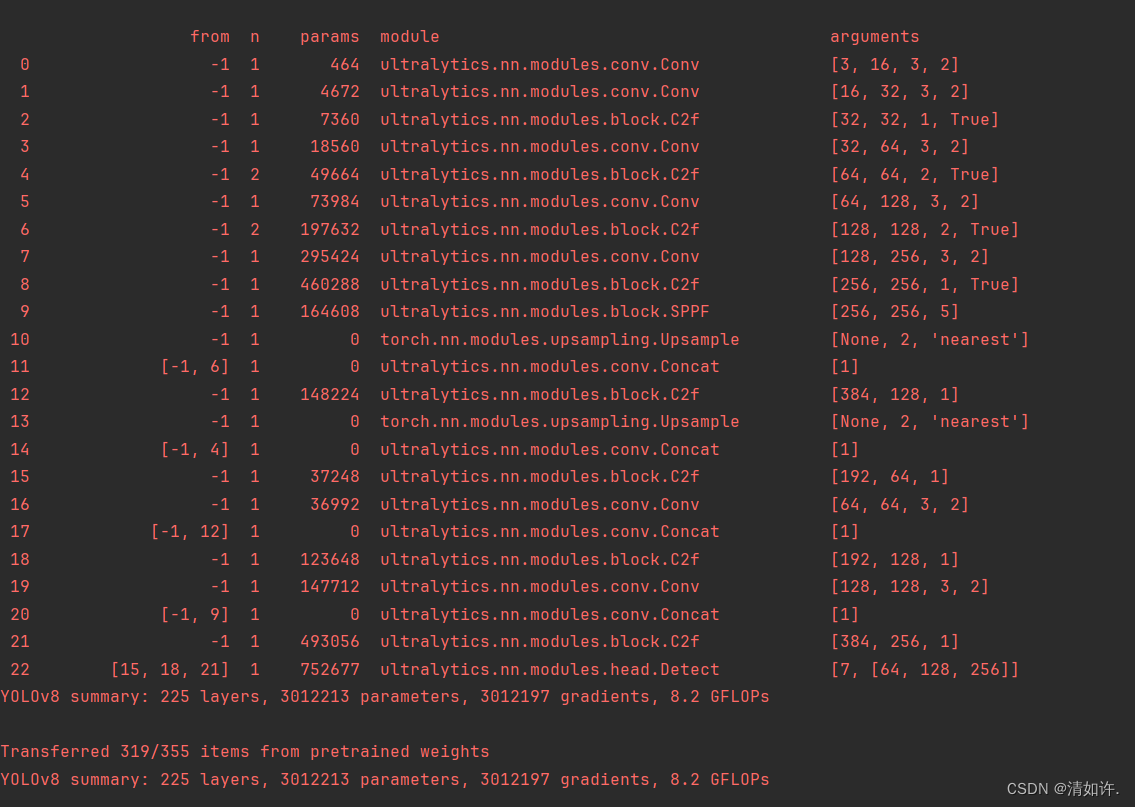
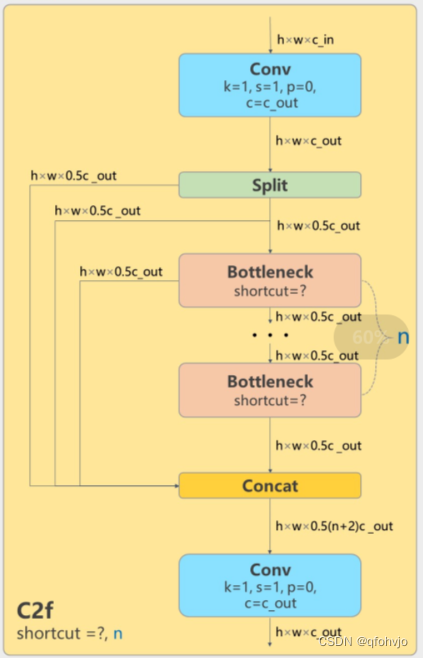
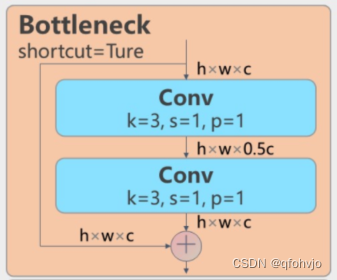
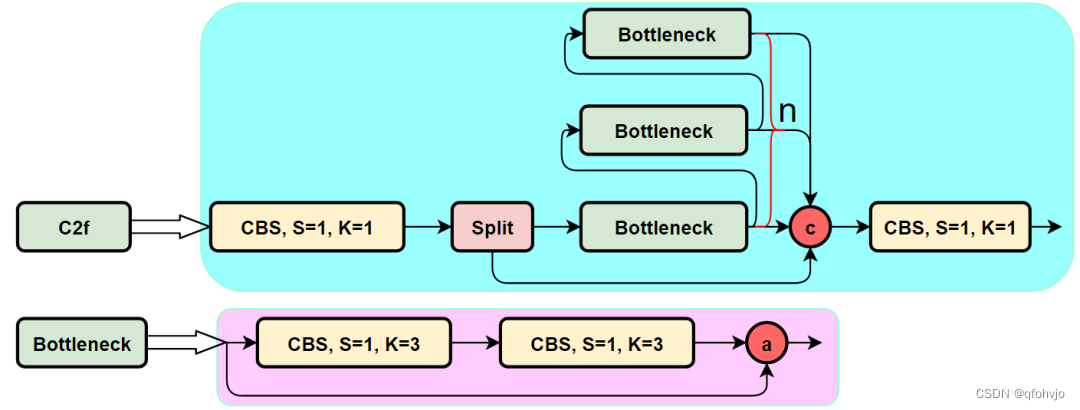
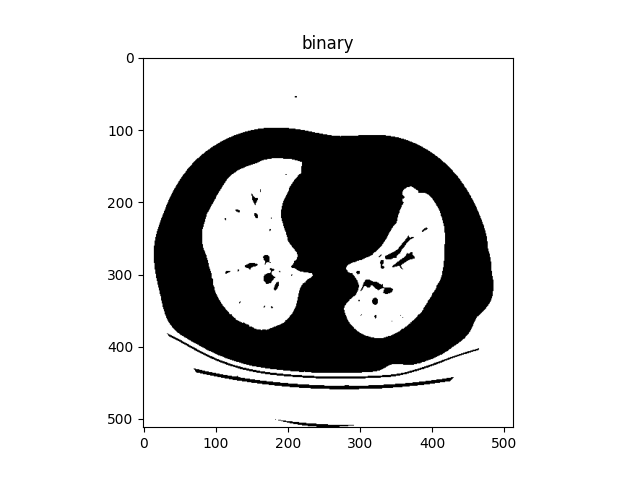
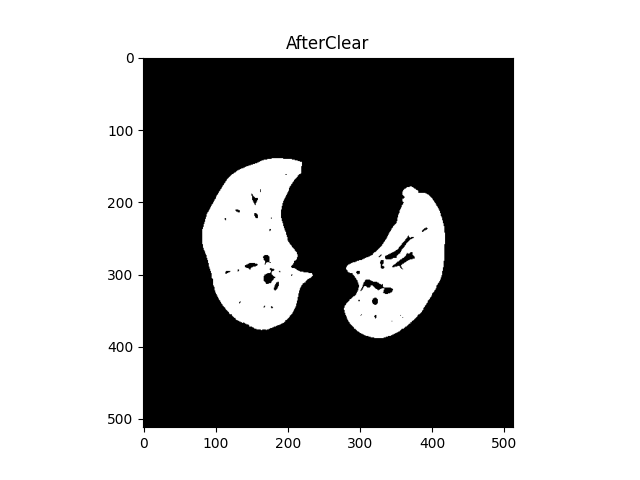
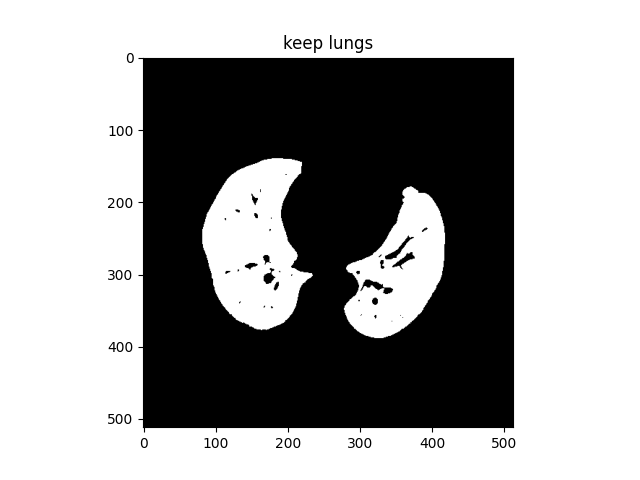
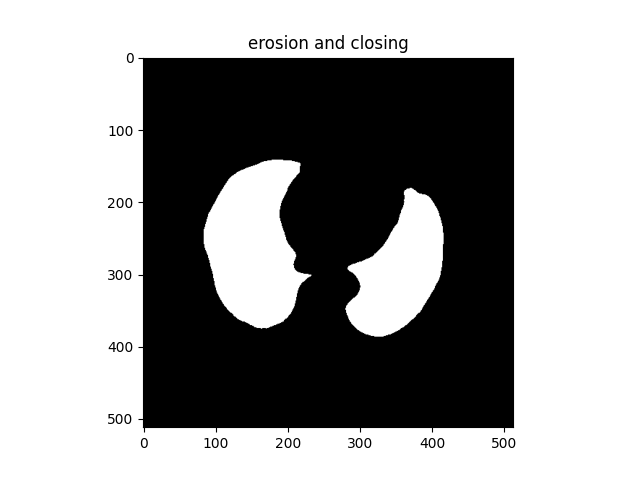
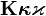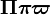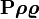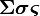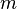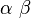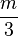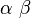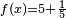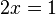1. 前言:
基于DICOM3.0标准的医学图像中,每一张图像中都携带着许多的信息,这些信息主要可以分为Patient, Study, Series和Image四类。每一个DICOM Tag都是由两个十六进制数的组合来确定的,分别为Group和Element。如(0010,0010)这个Tag表示的是Patient’s Name,它存储着这张DICOM图像的患者姓名。
在研发关于医学影像软件时,必然需要对导入的DICOM图像进行文件解析,很重要的一部分工作就是需要从图像中获取它所储存的信息,然后在开发的软件中根据需要显示出来。一般医学影像软件在显示某一张影像时会有四角信息,或者当医生在调整窗宽窗位值时,需要软件实时显示此时的值。
基于C++的DCMTK和基于Java的dcm4che,都是非常优秀的解释DICOM标准的第三方库,通过在工程中引入它们可以避免软件开发人员去进行底层的解析工作,可为项目开发提高效率。
以下是归纳的常见的DICOM Tag标签,和它们的描述和值表现(VR)。
| VR | 含义 | 允许
字符 |
数据长度 |
| CS – Code String
代码字符串
|
开头结尾可以有没有意义的空格的字符串,比如“CD123_4”
|
大写字母,0-9,空格以及下划线字符
|
最多 16 个字符
|
| SH – Short String
短字符串
|
短字符串,比如:电话号码,ID等
|
|
最多 16 个字符
|
| LO – Long String
长字符串
|
一个字符串,可能在开头、结尾填有空 格。比如“Introduction to DICOM”
|
|
最多 64 个字符
|
| ST – Short Text
短文本
|
可能包含一个或多个段落的字符串
|
|
最多 1024 个字符
|
| LT – Long Text
短文本
|
可能包含一个或多个锻炼的字符串,与LO相同,但可以更长
|
|
最多 10240 个字符
|
| UT – Unlimited Text
无限制文本
|
包含一个或多个段落的字符串,与 LT类似
|
|
最多(2的32次方–2)个字符
|
| AE – Application Entity
应用实体
|
标识一个设备的名称的字符串,开头和 结尾可以有无意义的字符。比如“MyPC01”
|
|
最多 16 个字符
|
| PN – Person Name
病人姓名
|
有插入符号(^)作为姓名分隔符的病人姓名。比如“SMITH^JOHN” “Morrison- Jones^Susan^^^Ph.D, Chief Executive Officer”
|
|
最多 64 个字符
|
| UI – Unique Identifier (UID)
唯一标识符
|
一个用作唯一标识各类项目的包含UID 的字符串。比如“1.2.840.10008.1.1”
|
0-9 和半角句号(.)
|
最多64 个字符
|
| DA – Date
日期
|
格式为 YYYYMMDD 的字符串;YYYY代表年;MM 代表月;DD 代表日。比 如“20050822”表示 2005 年 8月 22 日
|
0-9
|
8个字符
|
| TM – Time
时间
|
格式为 HHMMSS 的字符串。FRAC; HH 表示小时(范围“00”-“23”); MM 表示分钟(范围“00”-“59”); 而 FRAC 包含秒的小数部分,即百万分 之一秒。比如“183200.00” 表示下午 6:32
|
0-9 和半角句号(.)
|
最多 16 个字符
|
| DT – Date Time
日期时间
|
格式为 YYYYMMDDHHMMSS. FFFFFF,串联的日期时间字符串。字符串的各部分从左至右是:年 YYYY;月 MM;日 DD;小时 HH;分钟MM;秒 SS;秒的小数 FFFFFF。比如 20050812183000.00”表示2005 年 8 月 12 日下午 18 点 30分 00 秒
|
0-9,加号,减号和半角句号
|
最多 26 个字符
|
| AS – Age String
年龄字符串
|
符合以下格式的字符串:nnnD,nnnW, nnnM, nnnY;其中 nnn对于 D 来说表示天数,对于W来说表示周数,对于M 来说表示月数,对于Y 来说表示岁数。 比如“018M”表示他的年龄是 18 个月
|
0–9, D,W,M, Y
|
4 个字符
|
| IS – Integer String
整型字符串
|
表示一个整型数字的字符串。比如“-1234567”
|
0-9,加号(+),减号(-)
|
最多 12 个字符
|
| DS – Decimal String 小数字符串
|
表示定点小数和浮点小数。 比如“12345.67”,“-5.0e3”
|
0-9,加号(+),减号(-), 最多16 个字符E,e 和半角句号(.)
|
最多 16 个字符
|
| SS – Signed Short
有符号短型
|
符号型二进制整数,长度 16 比特
|
|
2 个字符
|
| US – Unsigned Short 无符号短型
|
无符号二进制整数,长度 16 比特
|
|
2 个字符
|
| SL – Signed Long
有符号长型
|
有符号二进制整数
|
|
4 个字符
|
| UL – Unsigned Long 无符号长型
|
无符号二进制整数,长度 32 比特
|
|
4 个字符
|
| AT – Attribute Tag
属性标签
|
16 比特无符号整数的有序对,数据元素的标签
|
|
4 个字符
|
| FL – Floating Single 单精度浮点
|
单精度二进制浮点数字
|
|
4 个字符
|
| FD – Floating Point Double
双精度二进制浮点数字
|
双精度二进制浮点数字
|
|
8 个字符
|
| OB – Other Byte String
其他字节字符串
|
字节的字符串(“其他”表示没有在VR中定义的内容)
|
|
|
| OW – Other Word String
其他单词字符串
|
16 比特(2 字节)单词字符串
|
|
|
| OF – Other Float String
其他浮点字符串
|
32 比特(4 个字节)浮点单词字符串
|
|
|
| SQ – Sequence Items
条目序列
|
条目的序列
|
|
|
| UN – Unknown
未知
|
字节的字符串,其中内容的编码方式是未知的
|
|
|
3. DICOM TAG分类和说明
Patient Tag
| Group | Element | Tag Description | 中文解释
|
VR |
| 0010
|
0010
|
Patient’s Name | 患者姓名
|
PN |
| 0010
|
0020
|
Patient ID | 患者ID
|
LO |
| 0010
|
0030
|
Patient’s Birth Date | 患者出生日期
|
DA |
| 0010
|
0032
|
Patient’s Birth Time | 患者出生时间
|
TM |
| 0010
|
0040
|
Patient’s Sex | 患者性别
|
CS |
| 0010
|
1030
|
Patient’s Weight | 患者体重
|
DS |
| 0010
|
21C0
|
Pregnancy Status | 怀孕状态
|
US |
Study Tag
| Group | Element | Tag Description | 中文解释 | VR |
| 0008
|
0050
|
Accession Number:
A RIS generated number that identifies the order for the Study. |
检查号:
RIS的生成序号,用以标识做检查的次序.
|
SH |
| 0020
|
0010
|
Study ID
|
检查ID.
|
SH
|
| 0020
|
000D
|
Study Instance UID:
Unique identifier for the Study.
|
检查实例号:
唯一标记不同检查的号码.
|
UI
|
| 0008
|
0020
|
Study Date:
Date the Study started. |
检查日期:
检查开始的日期.
|
DA |
| 0008
|
0030
|
Study Time:
Time the Study started. |
检查时间:
检查开始的时间.
|
TM |
| 0008
|
0061
|
Modalities in Study | 一个检查中含有的不同检查类型.
|
CS |
| 0008
|
0015
|
Body Part Examined | 检查的部位.
|
CS |
| 0008
|
1030
|
Study Description | 检查的描述.
|
LO |
| 0010
|
1010
|
Patient’s Age | 做检查时刻的患者年龄,而不是此刻患者的真实年龄.
|
AS |
Series Tag
| Group | Element | Tag Description | 中文解释 | VR |
| 0020 | 0011 | Series Number:
A number that identifies this Series. |
序列号:
识别不同检查的号码. |
IS |
| 0020 | 000E | Series Instance UID:
Unique identifier for the Series. |
序列实例号:
唯一标记不同序列的号码. |
UI |
| 0008 | 0060 | Modality | 检查模态(MRI/CT/CR/DR) | CS |
| 0008 | 103E | Series Description | 检查描述和说明 | LO |
| 0008 | 0021 | Series Date | 检查日期 | DA |
| 0008 | 0031 | Series Time | 检查时间 | TM |
| 0020 | 0032 | Image Position (Patient):
The x, y and z coordinates of the upper left hand corner of the image, in mm. |
图像位置:
图像的左上角在空间坐标系中的x,y,z坐标,单位是毫米. 如果在检查中,则指该序列中第一张影像左上角的坐标. |
DS |
| 0020 | 0037 | Image Orientation (Patient):
The direction cosines of the first row and the first column with respect to the patient. |
图像方位: | DS |
| 0018 | 0050 | Slice Thickness:
Nominal slice thickness, in mm. |
层厚. | DS |
| 0018 | 0088 | Spacing Between Slices | 层与层之间的间距,单位为mm | DS |
| 0020 | 1041 | Slice Location:
Relative position of exposure expressed in mm. |
实际的相对位置,单位为mm. | DS |
| 0018 | 0023 | MR Acquisition | CS | |
| 0018 | 0015 | Body Part Examined | 身体部位. | CS |
Image Tag
| Group | Element | Tag Description | 中文解释
|
VR |
| 0008
|
0008
|
Image Type:
Image identification characteristics. |
|
CS |
| 0008
|
0018
|
SOP Instance UID | SOP实例UID.
|
|
| 0008
|
0023
|
Content Date:
The date the image pixel data creation started. |
影像拍摄的日期.
|
DA |
| 0008
|
0033
|
Content Time | 影像拍摄的时间.
|
TM |
| 0020
|
0013
|
Image/Instance Number:
A number that identifies this image. |
图像码:
辨识图像的号码.
|
IS |
| 0028
|
0002
|
Samples Per Pixel:
Number of samples (planes) in this image. |
图像上的采样率.
|
US |
| 0028
|
0004
|
Photometric Interpretation:
Specifies the intended interpretation of the pixel data. |
光度计的解释,对于CT图像,用两个枚举值
MONOCHROME1,MONOCHROME2.
用来判断图像是否是彩色的,
MONOCHROME1/2是灰度图,
RGB则是真彩色图,还有其他.
|
CS |
| 0028
|
0010
|
Rows: Number of rows in the image. | 图像的总行数,行分辨率.
|
US |
| 0028
|
0011
|
Columns: Number of columns in the image. | 图像的总列数,列分辨率.
|
US |
| 0028
|
0030
|
Pixel Spacing:
Physical distance in the patient between the center of each pixel. |
像素间距.
像素中心之间的物理间距.
|
DS |
| 0028
|
0100
|
Bits Allocated:
Number of bits allocated for each pixel sample. Each sample shall have the same number of bits allocated. |
分配的位数:
存储每一个像素值时分配的位数,每一个样本应该拥有相同的这个值.
|
US |
| 0028
|
0101
|
Bits Stored:
Number of bits stored for each pixel sample. Each sample shall have the same number of bits stored. |
存储的位数:有12到16列举值.
存储每一个像素用的位数.每一个样本应该有相同值.
|
US |
| 0028
|
0102
|
High Bit:
Most significant bit for pixel sample data. Each sample shall have the same high bit. |
高位.
|
US |
| 0028
|
0103
|
Pixel Representation:
Data representation of the pixel samples. Each sample shall have the same pixel representation. Enum: 0000H=unsigned integer, 0001H=2’s complement. |
像素数据的表现类型:
这是一个枚举值,分别为十六进制数0000和0001.
0000H = 无符号整数,
0001H = 2的补码.
|
US |
| 0028
|
1050
|
Window Center | 窗位.
|
DS |
| 0028
|
1051
|
Window Width | 窗宽.
|
DS |
| 0028
|
1052
|
Rescale Intercept:
The value b in relationship between stored values (SV) and the output units. Output units = m*SV + b. Required if Modality LUT Sequence (0028, 0030) is not present. |
截距:
如果表明不同模态的LUT颜色对应表不存在时,则使用方程
Units = m*SV + b,计算真实的像素值到呈现像素值。
其中这个值为表达式中的b。
|
DS |
| 0028
|
1053
|
Rescale Slope:
m in the equation specified by Rescale Intercept (0028,1052). Required if Rescale Intercept is present. |
斜率.
这个值为表达式中的m。
|
DS |
| 0028
|
1054
|
Rescale Type:
Specifies the output units of Rescale Slope (0028,1053) and Rescale Intercept (0028,1052). Enum: US=Unspecified Requried if Photometric Interpretation is MONOCHROME2, and Bits Stored is greater than 1. This specifies an identity Modality LUT transformation. |
输出值的单位.
这是一个枚举值,
|
LO |
1. 前言:
基于DICOM3.0标准的医学图像中,每一张图像中都携带着许多的信息,这些信息主要可以分为Patient, Study, Series和Image四类。每一个DICOM Tag都是由两个十六进制数的组合来确定的,分别为Group和Element。如(0010,0010)这个Tag表示的是Patient’s Name,它存储着这张DICOM图像的患者姓名。
在研发关于医学影像软件时,必然需要对导入的DICOM图像进行文件解析,很重要的一部分工作就是需要从图像中获取它所储存的信息,然后在开发的软件中根据需要显示出来。一般医学影像软件在显示某一张影像时会有四角信息,或者当医生在调整窗宽窗位值时,需要软件实时显示此时的值。
基于C++的DCMTK和基于Java的dcm4che,都是非常优秀的解释DICOM标准的第三方库,通过在工程中引入它们可以避免软件开发人员去进行底层的解析工作,可为项目开发提高效率。
以下是归纳的常见的DICOM Tag标签,和它们的描述和值表现(VR)。
2. VR
VR是DICOM标准中用来描述数据类型的,总共有27个值。简单分类如下:
| VR | 含义 | 允许
字符 |
数据长度 |
| CS – Code String
代码字符串
|
开头结尾可以有没有意义的空格的字符串,比如“CD123_4”
|
大写字母,0-9,空格以及下划线字符
|
最多 16 个字符
|
| SH – Short String
短字符串
|
短字符串,比如:电话号码,ID等
|
|
最多 16 个字符
|
| LO – Long String
长字符串
|
一个字符串,可能在开头、结尾填有空 格。比如“Introduction to DICOM”
|
|
最多 64 个字符
|
| ST – Short Text
短文本
|
可能包含一个或多个段落的字符串
|
|
最多 1024 个字符
|
| LT – Long Text
短文本
|
可能包含一个或多个锻炼的字符串,与LO相同,但可以更长
|
|
最多 10240 个字符
|
| UT – Unlimited Text
无限制文本
|
包含一个或多个段落的字符串,与 LT类似
|
|
最多(2的32次方–2)个字符
|
| AE – Application Entity
应用实体
|
标识一个设备的名称的字符串,开头和 结尾可以有无意义的字符。比如“MyPC01”
|
|
最多 16 个字符
|
| PN – Person Name
病人姓名
|
有插入符号(^)作为姓名分隔符的病人姓名。比如“SMITH^JOHN” “Morrison- Jones^Susan^^^Ph.D, Chief Executive Officer”
|
|
最多 64 个字符
|
| UI – Unique Identifier (UID)
唯一标识符
|
一个用作唯一标识各类项目的包含UID 的字符串。比如“1.2.840.10008.1.1”
|
0-9 和半角句号(.)
|
最多64 个字符
|
| DA – Date
日期
|
格式为 YYYYMMDD 的字符串;YYYY代表年;MM 代表月;DD 代表日。比 如“20050822”表示 2005 年 8月 22 日
|
0-9
|
8个字符
|
| TM – Time
时间
|
格式为 HHMMSS 的字符串。FRAC; HH 表示小时(范围“00”-“23”); MM 表示分钟(范围“00”-“59”); 而 FRAC 包含秒的小数部分,即百万分 之一秒。比如“183200.00” 表示下午 6:32
|
0-9 和半角句号(.)
|
最多 16 个字符
|
| DT – Date Time
日期时间
|
格式为 YYYYMMDDHHMMSS. FFFFFF,串联的日期时间字符串。字符串的各部分从左至右是:年 YYYY;月 MM;日 DD;小时 HH;分钟MM;秒 SS;秒的小数 FFFFFF。比如 20050812183000.00”表示2005 年 8 月 12 日下午 18 点 30分 00 秒
|
0-9,加号,减号和半角句号
|
最多 26 个字符
|
| AS – Age String
年龄字符串
|
符合以下格式的字符串:nnnD,nnnW, nnnM, nnnY;其中 nnn对于 D 来说表示天数,对于W来说表示周数,对于M 来说表示月数,对于Y 来说表示岁数。 比如“018M”表示他的年龄是 18 个月
|
0–9, D,W,M, Y
|
4 个字符
|
| IS – Integer String
整型字符串
|
表示一个整型数字的字符串。比如“-1234567”
|
0-9,加号(+),减号(-)
|
最多 12 个字符
|
| DS – Decimal String 小数字符串
|
表示定点小数和浮点小数。 比如“12345.67”,“-5.0e3”
|
0-9,加号(+),减号(-), 最多16 个字符E,e 和半角句号(.)
|
最多 16 个字符
|
| SS – Signed Short
有符号短型
|
符号型二进制整数,长度 16 比特
|
|
2 个字符
|
| US – Unsigned Short 无符号短型
|
无符号二进制整数,长度 16 比特
|
|
2 个字符
|
| SL – Signed Long
有符号长型
|
有符号二进制整数
|
|
4 个字符
|
| UL – Unsigned Long 无符号长型
|
无符号二进制整数,长度 32 比特
|
|
4 个字符
|
| AT – Attribute Tag
属性标签
|
16 比特无符号整数的有序对,数据元素的标签
|
|
4 个字符
|
| FL – Floating Single 单精度浮点
|
单精度二进制浮点数字
|
|
4 个字符
|
| FD – Floating Point Double
双精度二进制浮点数字
|
双精度二进制浮点数字
|
|
8 个字符
|
| OB – Other Byte String
其他字节字符串
|
字节的字符串(“其他”表示没有在VR中定义的内容)
|
|
|
| OW – Other Word String
其他单词字符串
|
16 比特(2 字节)单词字符串
|
|
|
| OF – Other Float String
其他浮点字符串
|
32 比特(4 个字节)浮点单词字符串
|
|
|
| SQ – Sequence Items
条目序列
|
条目的序列
|
|
|
| UN – Unknown
未知
|
字节的字符串,其中内容的编码方式是未知的
|
|
|
3. DICOM TAG分类和说明
Patient Tag
| Group | Element | Tag Description | 中文解释
|
VR |
| 0010
|
0010
|
Patient’s Name | 患者姓名
|
PN |
| 0010
|
0020
|
Patient ID | 患者ID
|
LO |
| 0010
|
0030
|
Patient’s Birth Date | 患者出生日期
|
DA |
| 0010
|
0032
|
Patient’s Birth Time | 患者出生时间
|
TM |
| 0010
|
0040
|
Patient’s Sex | 患者性别
|
CS |
| 0010
|
1030
|
Patient’s Weight | 患者体重
|
DS |
| 0010
|
21C0
|
Pregnancy Status | 怀孕状态
|
US |
Study Tag
| Group | Element | Tag Description | 中文解释 | VR |
| 0008
|
0050
|
Accession Number:
A RIS generated number that identifies the order for the Study. |
检查号:
RIS的生成序号,用以标识做检查的次序.
|
SH |
| 0020
|
0010
|
Study ID
|
检查ID.
|
SH
|
| 0020
|
000D
|
Study Instance UID:
Unique identifier for the Study.
|
检查实例号:
唯一标记不同检查的号码.
|
UI
|
| 0008
|
0020
|
Study Date:
Date the Study started. |
检查日期:
检查开始的日期.
|
DA |
| 0008
|
0030
|
Study Time:
Time the Study started. |
检查时间:
检查开始的时间.
|
TM |
| 0008
|
0061
|
Modalities in Study | 一个检查中含有的不同检查类型.
|
CS |
| 0008
|
0015
|
Body Part Examined | 检查的部位.
|
CS |
| 0008
|
1030
|
Study Description | 检查的描述.
|
LO |
| 0010
|
1010
|
Patient’s Age | 做检查时刻的患者年龄,而不是此刻患者的真实年龄.
|
AS |
Series Tag
| Group | Element | Tag Description | 中文解释 | VR |
| 0020 | 0011 | Series Number:
A number that identifies this Series. |
序列号:
识别不同检查的号码. |
IS |
| 0020 | 000E | Series Instance UID:
Unique identifier for the Series. |
序列实例号:
唯一标记不同序列的号码. |
UI |
| 0008 | 0060 | Modality | 检查模态(MRI/CT/CR/DR) | CS |
| 0008 | 103E | Series Description | 检查描述和说明 | LO |
| 0008 | 0021 | Series Date | 检查日期 | DA |
| 0008 | 0031 | Series Time | 检查时间 | TM |
| 0020 | 0032 | Image Position (Patient):
The x, y and z coordinates of the upper left hand corner of the image, in mm. |
图像位置:
图像的左上角在空间坐标系中的x,y,z坐标,单位是毫米. 如果在检查中,则指该序列中第一张影像左上角的坐标. |
DS |
| 0020 | 0037 | Image Orientation (Patient):
The direction cosines of the first row and the first column with respect to the patient. |
图像方位: | DS |
| 0018 | 0050 | Slice Thickness:
Nominal slice thickness, in mm. |
层厚. | DS |
| 0018 | 0088 | Spacing Between Slices | 层与层之间的间距,单位为mm | DS |
| 0020 | 1041 | Slice Location:
Relative position of exposure expressed in mm. |
实际的相对位置,单位为mm. | DS |
| 0018 | 0023 | MR Acquisition | CS | |
| 0018 | 0015 | Body Part Examined | 身体部位. | CS |
Image Tag
| Group | Element | Tag Description | 中文解释
|
VR |
| 0008
|
0008
|
Image Type:
Image identification characteristics. |
|
CS |
| 0008
|
0018
|
SOP Instance UID | SOP实例UID.
|
|
| 0008
|
0023
|
Content Date:
The date the image pixel data creation started. |
影像拍摄的日期.
|
DA |
| 0008
|
0033
|
Content Time | 影像拍摄的时间.
|
TM |
| 0020
|
0013
|
Image/Instance Number:
A number that identifies this image. |
图像码:
辨识图像的号码.
|
IS |
| 0028
|
0002
|
Samples Per Pixel:
Number of samples (planes) in this image. |
图像上的采样率.
|
US |
| 0028
|
0004
|
Photometric Interpretation:
Specifies the intended interpretation of the pixel data. |
光度计的解释,对于CT图像,用两个枚举值
MONOCHROME1,MONOCHROME2.
用来判断图像是否是彩色的,
MONOCHROME1/2是灰度图,
RGB则是真彩色图,还有其他.
|
CS |
| 0028
|
0010
|
Rows: Number of rows in the image. | 图像的总行数,行分辨率.
|
US |
| 0028
|
0011
|
Columns: Number of columns in the image. | 图像的总列数,列分辨率.
|
US |
| 0028
|
0030
|
Pixel Spacing:
Physical distance in the patient between the center of each pixel. |
像素间距.
像素中心之间的物理间距.
|
DS |
| 0028
|
0100
|
Bits Allocated:
Number of bits allocated for each pixel sample. Each sample shall have the same number of bits allocated. |
分配的位数:
存储每一个像素值时分配的位数,每一个样本应该拥有相同的这个值.
|
US |
| 0028
|
0101
|
Bits Stored:
Number of bits stored for each pixel sample. Each sample shall have the same number of bits stored. |
存储的位数:有12到16列举值.
存储每一个像素用的位数.每一个样本应该有相同值.
|
US |
| 0028
|
0102
|
High Bit:
Most significant bit for pixel sample data. Each sample shall have the same high bit. |
高位.
|
US |
| 0028
|
0103
|
Pixel Representation:
Data representation of the pixel samples. Each sample shall have the same pixel representation. Enum: 0000H=unsigned integer, 0001H=2’s complement. |
像素数据的表现类型:
这是一个枚举值,分别为十六进制数0000和0001.
0000H = 无符号整数,
0001H = 2的补码.
|
US |
| 0028
|
1050
|
Window Center | 窗位.
|
DS |
| 0028
|
1051
|
Window Width | 窗宽.
|
DS |
| 0028
|
1052
|
Rescale Intercept:
The value b in relationship between stored values (SV) and the output units. Output units = m*SV + b. Required if Modality LUT Sequence (0028, 0030) is not present. |
截距:
如果表明不同模态的LUT颜色对应表不存在时,则使用方程
Units = m*SV + b,计算真实的像素值到呈现像素值。
其中这个值为表达式中的b。
|
DS |
| 0028
|
1053
|
Rescale Slope:
m in the equation specified by Rescale Intercept (0028,1052). Required if Rescale Intercept is present. |
斜率.
这个值为表达式中的m。
|
DS |
| 0028
|
1054
|
Rescale Type:
Specifies the output units of Rescale Slope (0028,1053) and Rescale Intercept (0028,1052). Enum: US=Unspecified Requried if Photometric Interpretation is MONOCHROME2, and Bits Stored is greater than 1. This specifies an identity Modality LUT transformation. |
输出值的单位.
这是一个枚举值,
|
LO |
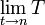
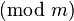

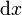
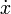
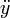









![pagecolor{White}sqrt[n]{3}](/wp-content/uploads/replace/21cb8585a0a0b036ee2109bb1d68eb1e.png)