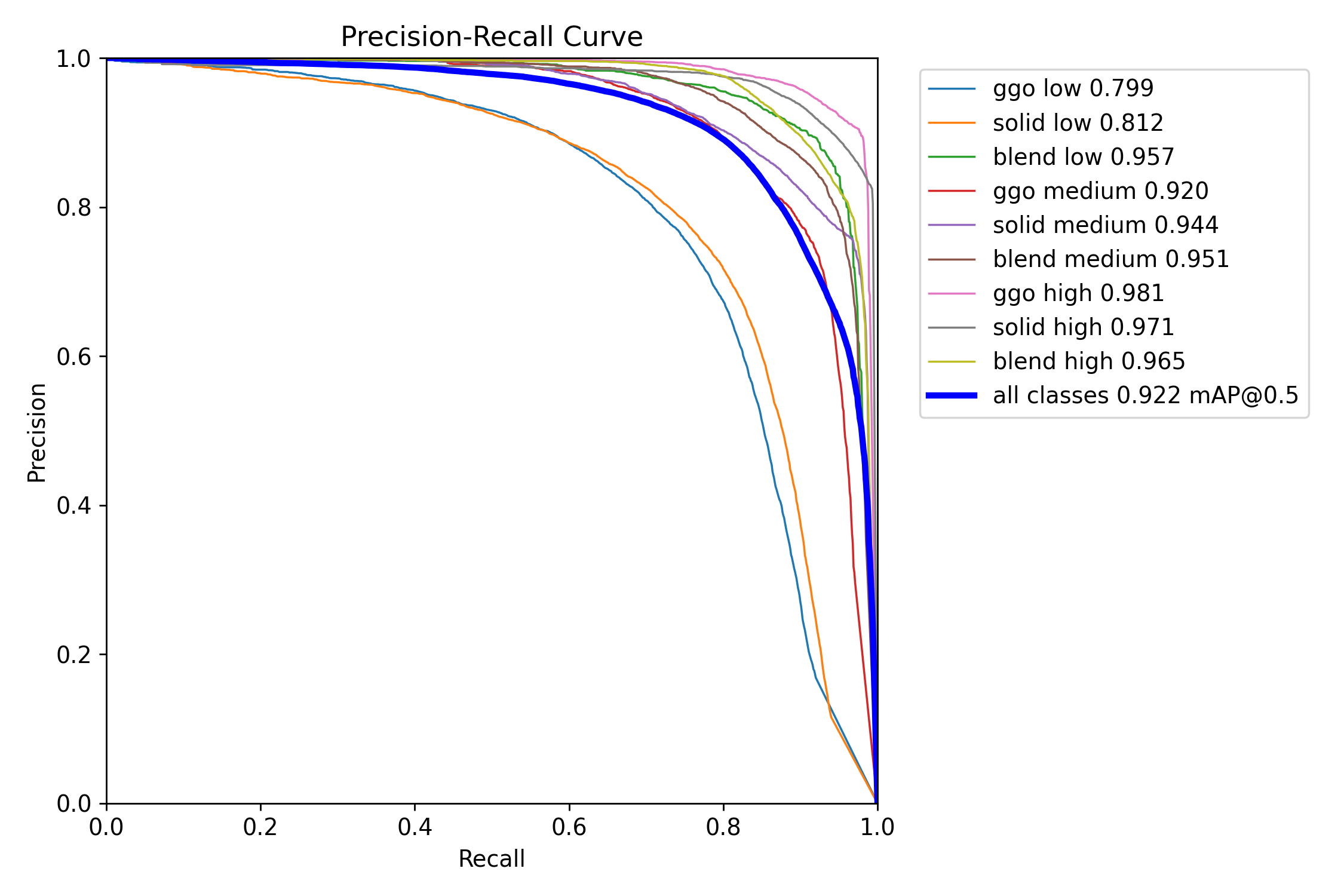
在维护服务器的过程中,有时候会出现一些进程没人认领,这个时候会影响资源的合理分配,也担心系统被人入侵。使用nvidia-smi 以及htop,top也只能知道是哪个进程(PID)占用的资源,但是并不能知道是谁的程序。此时可以通过ll /proc/PID 指令来查看进程所属的目录从而就可以知道是谁的程序了。
nvidia-smi
Thu Feb 22 09:16:48 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.154.05 Driver Version: 535.154.05 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 On | Off |
| 31% 59C P2 347W / 450W | 8845MiB / 24564MiB | 98% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 2178 G /usr/lib/xorg/Xorg 116MiB |
| 0 N/A N/A 2410 G /usr/bin/gnome-shell 69MiB |
| 0 N/A N/A 2017416 C python 8642MiB |
+---------------------------------------------------------------------------------------+
top
2017416 ai 20 0 27.1g 4.2g 2.0g S 113.3 13.6 783:50.75 python
2018057 ai 20 0 14.7g 2.0g 96436 S 40.0 6.4 61:15.49 python
1 root 20 0 166760 8448 5632 S 0.0 0.0 0:03.58 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.07 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
5 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 slub_flushwq
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 netns
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-events_highpri
11 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
12 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_kthread
13 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_rude_kthread
14 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_trace_kthread
15 root 20 0 0 0 0 S 0.0 0.0 0:05.19 ksoftirqd/0
16 root 20 0 0 0 0 I 0.0 0.0 3:19.23 rcu_preempt
17 root rt 0 0 0 0 S 0.0 0.0 0:01.70 migration/0
18 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject/0
19 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0
20 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/2
21 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject/2
22 root rt 0 0 0 0 S 0.0 0.0 0:01.61 migration/2
23 root 20 0 0 0 0 S 0.0 0.0 0:03.92 ksoftirqd/2
25 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/2:0H-events_highpri
26 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/4
27 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject/4
28 root rt 0 0 0 0 S 0.0 0.0 0:01.69 migration/4
29 root 20 0 0 0 0 S 0.0 0.0 0:04.04 ksoftirqd/4
31 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/4:0H-events_highpri
32 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/6
33 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject/6
htop
0[|| 1.3%] 4[|| 2.6%] 8[|||||| 20.3%] 12[||| 7.7%] 16[| 0.7%] 20[ 0.0%] 24[ 0.0%] 28[ 0.0%]
1[| 0.7%] 5[ 0.0%] 9[||||||||| 36.8%] 13[ 0.0%] 17[ 0.0%] 21[ 0.0%] 25[ 0.0%] 29[ 0.0%]
2[| 2.6%] 6[||| 5.8%] 10[|||||||||||||| 54.6%] 14[||| 7.1%] 18[| 0.7%] 22[ 0.0%] 26[ 0.0%] 30[ 0.0%]
3[|| 1.3%] 7[ 0.0%] 11[|| 3.3%] 15[ 0.0%] 19[ 0.0%] 23[ 0.0%] 27[ 0.0%] 31[ 0.0%]
Mem[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||18.0G/31.1G] Tasks: 166, 511 thr, 349 kthr; 0 running
Swp[ 0K/0K] Load average: 1.36 2.26 11.68
Uptime: 2 days, 21:36:55
[Main] [I/O]
PID USER PRI NI VIRT RES SHR S CPU%▽MEM% TIME+ Command
2017416 ai 20 0 27.1G 4315M 2063M R 75.0 13.6 10h20:48 python train.py
2018408 ai 20 0 27.1G 4315M 2063M S 26.1 13.6 1h47:53 python train.py
2017993 ai 20 0 14.6G 1954M 96436 S 6.5 6.1 1h02:37 python train.py
2018025 ai 20 0 14.5G 1894M 96436 S 5.9 5.9 56:29.18 python train.py
2018057 ai 20 0 14.7G 2014M 96436 R 4.6 6.3 57:31.94 python train.py
2017929 ai 20 0 14.5G 1894M 96436 S 3.3 5.9 58:48.62 python train.py
2018089 ai 20 0 14.8G 2159M 97460 S 3.3 6.8 59:42.36 python train.py
2018121 ai 20 0 14.5G 1896M 97204 S 3.3 6.0 1h00:38 python train.py
2018153 ai 20 0 14.8G 2173M 97204 S 3.3 6.8 58:03.87 python train.py
2017961 ai 20 0 14.5G 1895M 97460 S 2.6 6.0 1h01:09 python train.py
2018154 ai 20 0 27.1G 4315M 2063M S 2.0 13.6 27:33.90 python train.py
2051932 ai 20 0 7264 5376 3072 R 2.0 0.0 0:00.13 /snap/htop/4079/usr/local/bin/htop
47203 ai 20 0 703M 10132 6656 S 0.7 0.0 0:30.88 ./natapp -authtoken=6067e3183f0dba3e
2018225 ai 20 0 14.7G 2014M 96436 S 0.7 6.3 3:32.35 python train.py
2018226 ai 20 0 14.8G 2173M 97204 S 0.7 6.8 3:40.85 python train.py
2018227 ai 20 0 14.5G 1894M 96436 S 0.7 5.9 3:53.54 python train.py
2018228 ai 20 0 14.6G 1954M 96436 S 0.7 6.1 3:32.01 python train.py
2018229 ai 20 0 14.5G 1894M 96436 S 0.7 5.9 3:44.15 python train.py
2018230 ai 20 0 14.5G 1896M 97204 S 0.7 6.0 3:33.56 python train.py
2018236 ai 20 0 14.8G 2159M 97460 S 0.7 6.8 3:47.90 python train.py
2018238 ai 20 0 14.5G 1895M 97460 S 0.7 6.0 3:35.48 python train.py
2023173 ai 20 0 18236 8120 5632 S 0.7 0.0 0:05.17 sshd: ai@pts/1,pts/2
2023241 ai 20 0 17644 4864 2816 S 0.7 0.0 0:02.69 top
2024703 ai 20 0 18076 8376 5632 S 0.7 0.0 0:03.87 sshd: ai@pts/3,pts/4
1 root 20 0 162M 8448 5632 S 0.0 0.0 0:03.57 /sbin/init splash
F1Help F2Setup F3SearchF4FilterF5Tree F6SortByF7Nice -F8Nice +F9Kill F10Quit
一、应用层
1.1 /proc/pid/exe
以top进程为例:
[root@localhost ~]# ps -ef | grep top
root 31386 15859 0 14:58 pts/2 00:00:00 top
top进程的pid为31386 ,可以通过查看 /proc/pid/exe:
在Linux系统中,每个进程都有一个/proc/pid/exe文件,它是一个符号链接文件,指向当前进程的可执行文件。
更具体地说,/proc/pid/exe文件是一个符号链接文件,它的内容是一个指向当前进程可执行文件的绝对路径的符号链接。例如,如果当前进程的可执行文件是/usr/bin/myprogram,那么/proc/pid/exe文件的内容将是/usr/bin/myprogram的绝对路径。
通过访问/proc/pid/exe文件,可以快速获取当前进程的可执行文件路径。
[root@localhost ~]# ls -l /proc/31386/exe
lrwxrwxrwx. 1 root root 0 5月 18 14:59 /proc/31386/exe -> /usr/bin/top
其中/usr/bin/top为top进程可执行文件所在的绝对文件路径。
由于/proc/31386/exe是符号链接,直接调用 readlink 命令获取该进程可执行文件所在的绝对文件路径:
[root@localhost ~]# readlink /proc/31386/exe
/usr/bin/top
其中/usr/bin/top为top进程可执行文件所在的绝对文件路径。
由于/proc/31386/exe是符号链接,直接调用 readlink 命令获取该进程可执行文件所在的绝对文件路径:
[root@localhost ~]# readlink /proc/31386/exe
/usr/bin/top
NAME
readlink - print resolved symbolic links or canonical file names
Print value of a symbolic link or canonical file name
#include
#include <linux/limits.h>
int main()
{
char task_absolute_path[PATH_MAX];
int cnt = readlink( "/proc/self/exe", task_absolute_path, PATH_MAX);
if (cnt < 0){
printf("readlink is error\n");
return -1;
}
task_absolute_path[cnt] = '\0';
printf("task absolute path:%s\n", task_absolute_path);
return 0;
}
readlink()函数用于读取符号链接文件的内容,符号链接文件的内容就是一个路径,即解析符号链接。使用 readlink 读取符号链接,获取的就是符号链接的内容,符号链接的内容的就是目标文件的路径。
当然对于top这种系统shell命令,可以用which和whereis查看:
[root@localhost ~]# which top
/usr/bin/top
[root@localhost ~]# whereis top
top: /usr/bin/top /usr/share/man/man1/top.1.gz
对于普通程序通常用 /proc/pid/exe进行查看。
1.2 /proc/pid/cwd
在Linux系统中,每个进程都有一个/proc/pid/cwd文件,它是一个符号链接文件,指向当前进程的工作目录。
如下所示,我在 /root/link/test1/ 目录下运行 top 命令。
[root@localhost ~]# ls -l /proc/31386/cwd
lrwxrwxrwx. 1 root root 0 5月 18 15:02 /proc/31386/cwd -> /root/link/test1
[root@localhost ~]# readlink /proc/31386/cwd
/root/link/test1
更具体地说,/proc/pid/cwd文件是一个符号链接文件,它的内容是一个指向进程号为 pid 工作目录的绝对路径的符号链接。例如,如果当前进程的工作目录是/home/user,那么/proc/pid/cwd文件的内容将是/home/user的绝对路径。
通过访问/proc/pid/cwd文件,可以快速获取当前进程的工作目录路径,而无需在程序中调用getcwd()函数等获取当前工作目录的系统调用。
需要注意的是,/proc/pid/cwd文件是一个符号链接文件,它指向的路径可能会随着进程的工作目录的变化而变化,因此在读取它的内容时,应该对返回值进行错误检查,以确保它确实指向当前进程的工作目录。
比如函数 getcwd():
NAME
getcwd, getwd, get_current_dir_name - get current working directory
SYNOPSIS
#include
char *getcwd(char *buf, size_t size);
1.3 代码示例
接下来给出一段代码,根据输入的参数进程pid号,开获取该进程可执行程序的绝对路径和当前在哪个目录执行:
#include
#include
#include
#include
#include <linux/limits.h>
#define PROC_PATH_LEN 64
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s \n", argv[0]);
exit(EXIT_FAILURE);
}
char proc_path[PROC_PATH_LEN] = {0};
snprintf(proc_path, sizeof(proc_path), "/proc/%s/exe", argv[1]);
char exe_path[PATH_MAX] = {0};
ssize_t len = readlink(proc_path, exe_path, sizeof(exe_path));
if (len == -1) {
perror("readlink");
exit(EXIT_FAILURE);
}
exe_path[len] = '\0';
printf("Executable path: %s\n", exe_path);
memset(proc_path, 0, PROC_PATH_LEN);
snprintf(proc_path, sizeof(proc_path), "/proc/%s/cwd", argv[1]);
char cwd_path[PATH_MAX] = {0};
len = readlink(proc_path, cwd_path, sizeof(cwd_path));
if (len == -1) {
perror("readlink");
exit(EXIT_FAILURE);
}
cwd_path[len] = '\0';
printf("pid current path: %s\n", cwd_path);
return 0;
}
二、内核态获取
2.1 相对应的函数与结构体
struct fs_struct *fs 描述了文件系统和进程相关的信息:
// linux-3.10/include/linux/sched.h
struct task_struct {
......
/* filesystem information */
struct fs_struct *fs;
......
}
// linux-3.10/include/linux/fs_struct.h
struct fs_struct {
int users;
spinlock_t lock;
seqcount_t seq;
int umask;
int in_exec;
struct path root, pwd;
};
其中 struct path root 表示根目录路径,通常都是 / 目录,但是通过chroot系统调用后,对于进程来说会将 / 目录变成了某个子目录,那么相应的进程就是使用该子目录而不是全局的根目录,该进程会将该子目录当作其根目录。
chroot - run command or interactive shell with special root directory
Run COMMAND with root directory set to NEWROOT.
struct path pwd就是当前工作目录。
// linux-3.10/include/linux/path.h
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
};
// linux-3.10/include/linux/dcache.h
/*
* "quick string" -- eases parameter passing, but more importantly
* saves "metadata" about the string (ie length and the hash).
*
* hash comes first so it snuggles against d_parent in the
* dentry.
*/
struct qstr {
......
const unsigned char *name;
};
struct dentry {
......
struct qstr d_name;
......
}
// linux-3.10/include/linux/sched.h
struct task_struct {
......
struct mm_struct *mm;
......
}
从task_struct获取路径基本通过mm_struct这个结构,从中可以获取进程全路径。
// 获取进程全路径
task_struct->mm->exe_file->f_path
将进程的所在的文件路径存储到 /proc//exe symlink中:
// linux-3.10/include/linux/mm_types.h
struct mm_struct {
......
/* store ref to file /proc//exe symlink points to */
struct file *exe_file;
......
}
// linux-3.10/include/linux/fs.h
struct file {
......
struct path f_path;
......
}
(1) 通过dentry_path_raw获取文件的全路径,低版本比如2.6.32没有该API
// linux-3.10/fs/dcache.c
static int prepend(char **buffer, int *buflen, const char *str, int namelen)
{
*buflen -= namelen;
if (*buflen < 0) return -ENAMETOOLONG; *buffer -= namelen; memcpy(*buffer, str, namelen); return 0; } static int prepend_name(char **buffer, int *buflen, struct qstr *name) { return prepend(buffer, buflen, name->name, name->len);
}
/*
* Write full pathname from the root of the filesystem into the buffer.
*/
static char *__dentry_path(struct dentry *dentry, char *buf, int buflen)
{
char *end = buf + buflen;
char *retval;
prepend(&end, &buflen, "\0", 1);
if (buflen < 1) goto Elong; /* Get '/' right */ retval = end-1; *retval = '/'; while (!IS_ROOT(dentry)) { struct dentry *parent = dentry->d_parent;
int error;
prefetch(parent);
spin_lock(&dentry->d_lock);
error = prepend_name(&end, &buflen, &dentry->d_name);
spin_unlock(&dentry->d_lock);
if (error != 0 || prepend(&end, &buflen, "/", 1) != 0)
goto Elong;
retval = end;
dentry = parent;
}
return retval;
Elong:
return ERR_PTR(-ENAMETOOLONG);
}
char *dentry_path_raw(struct dentry *dentry, char *buf, int buflen)
{
char *retval;
write_seqlock(&rename_lock);
retval = __dentry_path(dentry, buf, buflen);
write_sequnlock(&rename_lock);
return retval;
}
EXPORT_SYMBOL(dentry_path_raw);
struct file *filp;
dentry_path_raw(filp->f_path.dentry,buf,buflen);
(2)通过d_path获取文件的全路径
// linux-3.10/fs/dcache.c
/**
* d_path - return the path of a dentry
* @path: path to report
* @buf: buffer to return value in
* @buflen: buffer length
*
* Convert a dentry into an ASCII path name. If the entry has been deleted
* the string " (deleted)" is appended. Note that this is ambiguous.
*
* Returns a pointer into the buffer or an error code if the path was
* too long. Note: Callers should use the returned pointer, not the passed
* in buffer, to use the name! The implementation often starts at an offset
* into the buffer, and may leave 0 bytes at the start.
*
* "buflen" should be positive.
*/
char *d_path(const struct path *path, char *buf, int buflen)
{
char *res = buf + buflen;
struct path root;
int error;
/*
* We have various synthetic filesystems that never get mounted. On
* these filesystems dentries are never used for lookup purposes, and
* thus don't need to be hashed. They also don't need a name until a
* user wants to identify the object in /proc/pid/fd/. The little hack
* below allows us to generate a name for these objects on demand:
*/
if (path->dentry->d_op && path->dentry->d_op->d_dname)
return path->dentry->d_op->d_dname(path->dentry, buf, buflen);
get_fs_root(current->fs, &root);
br_read_lock(&vfsmount_lock);
write_seqlock(&rename_lock);
error = path_with_deleted(path, &root, &res, &buflen);
write_sequnlock(&rename_lock);
br_read_unlock(&vfsmount_lock);
if (error < 0)
res = ERR_PTR(error);
path_put(&root);
return res;
}
EXPORT_SYMBOL(d_path);
调用d_path函数文件的路径时,应该使用返回的指针而不是转递进去的参数 buf 。
原因是该函数的实现通常从缓冲区的偏移量开始。
内核中用到d_path的例子:
// linux-3.10/include/linux/mm_types.h
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
......
struct file * vm_file; /* File we map to (can be NULL). */
......
}
// linux-3.10/include/linux/fs.h
struct file {
......
struct path f_path;
......
}
// linux-3.10/mm/memory.c
/*
* Print the name of a VMA.
*/
void print_vma_addr(char *prefix, unsigned long ip)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
/*
* Do not print if we are in atomic
* contexts (in exception stacks, etc.):
*/
if (preempt_count())
return;
down_read(&mm->mmap_sem);
vma = find_vma(mm, ip);
if (vma && vma->vm_file) {
struct file *f = vma->vm_file;
//使用伙伴系统接口,分配一个物理页,返回一个内核虚拟地址
char *buf = (char *)__get_free_page(GFP_KERNEL);
if (buf) {
char *p;
p = d_path(&f->f_path, buf, PAGE_SIZE);
if (IS_ERR(p))
p = "?";
printk("%s%s[%lx+%lx]", prefix, kbasename(p),
vma->vm_start,
vma->vm_end - vma->vm_start);
free_page((unsigned long)buf);
}
}
up_read(&mm->mmap_sem);
}
2.2 API演示
在这里只是简单的给出怎么在内核态获取进程所在文件的路径,详细的话请参考内核源码,在第三节给出内核源码获取进程所在文件的路径的方法。
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/sched.h>
#include <linux/pid.h>
#include <linux/fs.h>
#include <linux/fs_struct.h>
#include <linux/path.h>
#define TASK_PATH_MAX_LENGTH 512
//内核模块初始化函数
static int __init lkm_init(void)
{
struct qstr root_task_path;
struct qstr current_task_path;
char buf_1[TASK_PATH_MAX_LENGTH] = {0};
char *task_path_1 = NULL;
char buf_2[TASK_PATH_MAX_LENGTH] = {0};
char *task_path_2 = NULL;
//获取当前目录名
current_task_path = current->fs->pwd.dentry->d_name;
//获取根目录
root_task_path = current->fs->root.dentry->d_name;
//内核线程的 mm 成员为空,这里没做判断
//2.6.32 没有dentry_path_raw API
//获取文件全路径
task_path_1 = dentry_path_raw(current->mm->exe_file->f_path.dentry, buf_1, TASK_PATH_MAX_LENGTH);
//获取文件全路径
//调用d_path函数文件的路径时,应该使用返回的指针:task_path_2 ,而不是转递进去的参数buf:buf_2
task_path_2 = d_path(¤t->mm->exe_file->f_path, buf_2, TASK_PATH_MAX_LENGTH);
if (IS_ERR(task_path_2)) {
printk("Get path failed\n");
return -1;
}
printk("current path = %s\n", current_task_path.name);
printk("root path = %s\n", root_task_path.name);
printk("task_path_1 = %s\n", task_path_1);
printk("task_path_2 = %s\n", task_path_2);
return -1;
}
module_init(lkm_init);
MODULE_LICENSE("GPL");
结果展示:
[root@localhost task_path]# dmesg -c
[415299.952165] current path = task_path
[415299.952172] root path = /
[415299.952176] task_path_1 = /usr/bin/kmod
[415299.952179] task_path_2 = /usr/bin/kmod
三、内核源码实现
// linux-3.10/fs/proc/base.c
/* NOTE:
* Implementing inode permission operations in /proc is almost
* certainly an error. Permission checks need to happen during
* each system call not at open time. The reason is that most of
* what we wish to check for permissions in /proc varies at runtime.
*
* The classic example of a problem is opening file descriptors
* in /proc for a task before it execs a suid executable.
*/
struct pid_entry {
char *name;
int len;
umode_t mode;
const struct inode_operations *iop;
const struct file_operations *fop;
union proc_op op;
};
static int proc_exe_link(struct dentry *dentry, struct path *exe_path)
{
struct task_struct *task;
struct mm_struct *mm;
struct file *exe_file;
task = get_proc_task(dentry->d_inode);
if (!task)
return -ENOENT;
mm = get_task_mm(task);
put_task_struct(task);
if (!mm)
return -ENOENT;
exe_file = get_mm_exe_file(mm);
mmput(mm);
if (exe_file) {
*exe_path = exe_file->f_path;
path_get(&exe_file->f_path);
fput(exe_file);
return 0;
} else
return -ENOENT;
}
/*
* Tasks
*/
static const struct pid_entry tid_base_stuff[] = {
DIR("fd", S_IRUSR|S_IXUSR, proc_fd_inode_operations, proc_fd_operations),
......
REG("comm", S_IRUGO|S_IWUSR, proc_pid_set_comm_operations),
......
LNK("cwd", proc_cwd_link),
LNK("root", proc_root_link),
LNK("exe", proc_exe_link),
// linux-3.10/fs/proc/base.c
static int do_proc_readlink(struct path *path, char __user *buffer, int buflen)
{
//由于这里申请的是一个页大小,便没有使用 kmalloc接口,调用伙伴系统接口分配一个物理页,返回内核虚拟地址
char *tmp = (char*)__get_free_page(GFP_TEMPORARY);
char *pathname;
int len;
if (!tmp)
return -ENOMEM;
//获取进程所在文件的路径
pathname = d_path(path, tmp, PAGE_SIZE);
len = PTR_ERR(pathname);
if (IS_ERR(pathname))
goto out;
len = tmp + PAGE_SIZE - 1 - pathname;
if (len > buflen)
len = buflen;
//把进程所在文件的路径拷贝到用户空间:char __user *buffer
//用户空间调用 readlink /proc/pid/
if (copy_to_user(buffer, pathname, len))
len = -EFAULT;
out:
free_page((unsigned long)tmp);
return len;
}
static int proc_pid_readlink(struct dentry * dentry, char __user * buffer, int buflen)
{
int error = -EACCES;
struct inode *inode = dentry->d_inode;
struct path path;
/* Are we allowed to snoop on the tasks file descriptors? */
if (!proc_fd_access_allowed(inode))
goto out;
error = PROC_I(inode)->op.proc_get_link(dentry, &path);
if (error)
goto out;
error = do_proc_readlink(&path, buffer, buflen);
path_put(&path);
out:
return error;
}
const struct inode_operations proc_pid_link_inode_operations = {
.readlink = proc_pid_readlink,
.follow_link = proc_pid_follow_link,
.setattr = proc_setattr,
};
// linux-3.10/fs/proc/internal.h
union proc_op {
int (*proc_get_link)(struct dentry *, struct path *);
int (*proc_read)(struct task_struct *task, char *page);
int (*proc_show)(struct seq_file *m,
struct pid_namespace *ns, struct pid *pid,
struct task_struct *task);
};
struct proc_inode {
struct pid *pid;
int fd;
union proc_op op;
struct proc_dir_entry *pde;
struct ctl_table_header *sysctl;
struct ctl_table *sysctl_entry;
struct proc_ns ns;
struct inode vfs_inode;
};
/*
* General functions
*/
static inline struct proc_inode *PROC_I(const struct inode *inode)
{
return container_of(inode, struct proc_inode, vfs_inode);
}
其中:
proc_pid_readlink()
-->do_proc_readlink(){
char __user *buffer;
copy_to_user(buffer, pathname, len);
}
比如:当用户调用 readlink /proc/pid/exe,将该文件内容拷贝到用户空间:char __user *buffer中。